Машинне навчання є галуззю Штучний інтелект яка зосереджена на розробці моделей і алгоритмів, які дозволяють комп’ютерам навчатися на основі даних і вдосконалюватися на основі попереднього досвіду без явного програмування для кожного завдання. Простими словами, ML вчить системи думати й розуміти як люди, навчаючись на даних.
У цій статті ми розглянемо різні види алгоритми машинного навчання які важливі для майбутніх вимог. Машинне навчання це, як правило, система навчання для вивчення минулого досвіду та підвищення продуктивності з часом. Машинне навчання допомагає передбачити величезні обсяги даних. Це допомагає отримати швидкі та точні результати, щоб отримати прибуткові можливості.
Типи машинного навчання
Існує кілька типів машинного навчання, кожен із яких має особливі характеристики та застосування. Деякі з основних типів алгоритмів машинного навчання:
- Контрольоване машинне навчання
- Машинне навчання без нагляду
- Напівкероване машинне навчання
- Навчання з підкріпленням
Типи машинного навчання
1. Контрольоване машинне навчання
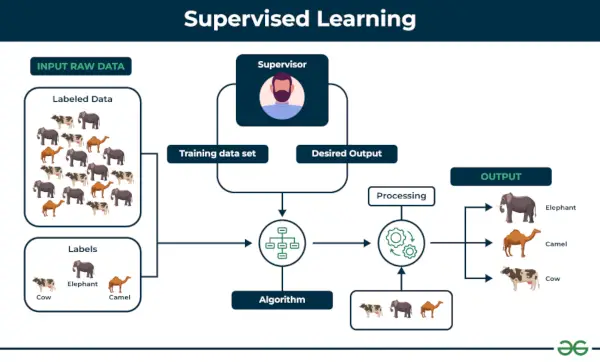
Контрольоване навчання визначається як коли модель проходить навчання на a Позначений набір даних . Помічені набори даних мають як вхідні, так і вихідні параметри. в Контрольоване навчання алгоритми вчаться відображати точки між входами та правильними виходами. Він має позначені набори даних для навчання та перевірки.
Контрольоване навчання
Розберемося в цьому на прикладі.
приклад: Розглянемо сценарій, коли вам потрібно створити класифікатор зображень, щоб розрізняти котів і собак. Якщо ви передаєте в алгоритм набори даних із зображеннями собак і котів, машина навчиться класифікувати собаку чи кішку за цими зображеннями. Коли ми вводимо нові зображення собаки чи кота, яких він ніколи раніше не бачив, він використовуватиме вивчені алгоритми та передбачатиме, собака це чи кіт. Ось як навчання під наглядом працює, і це, зокрема, класифікація зображень.
швета тіварі актор
Нижче наведено дві основні категорії навчання під наглядом:
- Класифікація
- регресія
Класифікація
Класифікація займається прогнозуванням категоричний цільові змінні, які представляють дискретні класи або мітки. Наприклад, класифікувати електронні листи як спам або не спам або прогнозувати, чи є у пацієнта високий ризик серцевих захворювань. Алгоритми класифікації вчаться зіставляти вхідні ознаки з одним із попередньо визначених класів.
Ось деякі алгоритми класифікації:
- Логістична регресія
- Підтримуюча векторна машина
- Випадковий ліс
- Дерево рішень
- K-найближчі сусіди (KNN)
- Наївний Байєс
регресія
регресія , з іншого боку, має справу з передбаченням безперервний цільові змінні, які представляють числові значення. Наприклад, прогнозування ціни будинку на основі його розміру, розташування та зручностей або прогнозування продажів продукту. Алгоритми регресії вчаться відображати вхідні характеристики безперервного числового значення.
Ось кілька алгоритмів регресії:
- Лінійна регресія
- Поліноміальна регресія
- Хребтова регресія
- Регресія ласо
- Дерево рішень
- Випадковий ліс
Переваги керованого машинного навчання
- Контрольоване навчання моделі можуть мати високу точність під час навчання позначені дані .
- Процес прийняття рішень у моделях навчання під наглядом часто можна інтерпретувати.
- Його часто можна використовувати в попередньо навчених моделях, що економить час і ресурси під час розробки нових моделей з нуля.
Недоліки керованого машинного навчання
- Він має обмеження у знанні шаблонів і може боротися з невидимими або неочікуваними шаблонами, яких немає в навчальних даних.
- Це може зайняти багато часу та коштувати, оскільки воно залежить від позначений лише дані.
- Це може призвести до поганих узагальнень на основі нових даних.
Застосування контрольованого навчання
Контрольоване навчання використовується в широкому спектрі застосувань, зокрема:
- Класифікація зображень : ідентифікуйте об’єкти, обличчя та інші елементи на зображеннях.
- Обробка природної мови: Отримайте з тексту інформацію, як-от почуття, сутності та зв’язки.
- Розпізнавання мови : перетворення розмовної мови на текст.
- Рекомендаційні системи : надавати персоналізовані рекомендації користувачам.
- Прогностична аналітика : прогнозуйте результати, такі як продажі, відтік клієнтів і ціни на акції.
- Медичний діагноз : виявлення захворювань та інших захворювань.
- Виявлення шахрайства : Виявляйте шахрайські транзакції.
- Автономні транспортні засоби : розпізнавати предмети в навколишньому середовищі та реагувати на них.
- Виявлення електронного спаму : класифікуйте електронні листи як спам чи ні.
- Контроль якості на виробництві : перевірити продукти на наявність дефектів.
- Кредитний скоринг : Оцініть ризик несплати позичальником кредиту.
- Ігри : розпізнавайте персонажів, аналізуйте поведінку гравців і створюйте NPC.
- Підтримка клієнтів : автоматизуйте завдання підтримки клієнтів.
- Прогнозування погоди : робити прогнози щодо температури, опадів та інших метеорологічних параметрів.
- Спортивна аналітика : Аналізуйте продуктивність гравців, робіть прогнози на гру та оптимізуйте стратегії.
2. Машинне навчання без нагляду
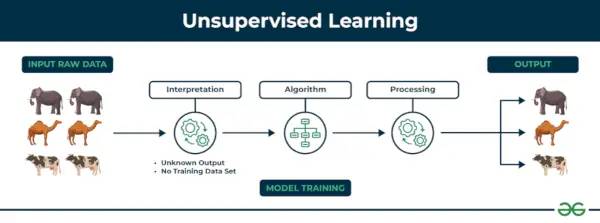
Навчання без контролю Неконтрольоване навчання – це тип техніки машинного навчання, у якому алгоритм виявляє шаблони та зв’язки, використовуючи дані без міток. На відміну від контрольованого навчання, неконтрольоване навчання не передбачає надання алгоритму позначених цільових результатів. Основною метою неконтрольованого навчання часто є виявлення прихованих шаблонів, подібностей або кластерів у даних, які потім можна використовувати для різних цілей, таких як дослідження даних, візуалізація, зменшення розмірності тощо.
Навчання без контролю
Розберемося в цьому на прикладі.
приклад: Вважайте, що у вас є набір даних, який містить інформацію про покупки, які ви зробили в магазині. Завдяки кластеризації алгоритм може згрупувати однакову купівельну поведінку серед вас та інших клієнтів, що виявляє потенційних клієнтів без попередньо визначених міток. Цей тип інформації може допомогти підприємствам знайти цільових клієнтів, а також виявити викиди.
Нижче наведено дві основні категорії неконтрольованого навчання:
- Кластеризація
- Асоціація
Кластеризація
Кластеризація це процес групування точок даних у кластери на основі їх подібності. Ця техніка корисна для виявлення закономірностей і зв’язків у даних без необхідності прикладів із мітками.
Ось деякі алгоритми кластеризації:
- Алгоритм кластеризації K-Means
- Алгоритм середнього зсуву
- Алгоритм DBSCAN
- Аналіз головних компонентів
- Незалежний аналіз компонентів
Асоціація
Вивчити правило асоціації ing — це техніка для виявлення зв’язків між елементами в наборі даних. Він визначає правила, які вказують на наявність одного елемента, передбачає наявність іншого елемента з певною ймовірністю.
Ось кілька алгоритмів навчання правил асоціації:
- Апріорний алгоритм
- Світіння
- Алгоритм FP-росту
Переваги неконтрольованого машинного навчання
- Це допомагає виявити приховані закономірності та різноманітні зв’язки між даними.
- Використовується для таких завдань, як сегментація клієнтів, виявлення аномалій, і дослідження даних .
- Він не потребує мічених даних і зменшує зусилля для маркування даних.
Недоліки неконтрольованого машинного навчання
- Без використання міток може бути важко передбачити якість результату моделі.
- Інтерпретація кластерів може бути неясною та не мати значущих інтерпретацій.
- Він має такі прийоми, як автокодери і зменшення розмірності які можна використовувати для отримання значущих функцій із необроблених даних.
Застосування неконтрольованого навчання
Ось кілька поширених застосувань неконтрольованого навчання:
- Кластеризація : згрупуйте схожі точки даних у кластери.
- Виявлення аномалії : виявлення викидів або аномалій у даних.
- Зменшення розмірності : Зменште розмірність даних, зберігаючи їх важливу інформацію.
- Рекомендаційні системи : пропонуйте користувачам продукти, фільми чи вміст на основі їхньої поведінки чи вподобань.
- Моделювання теми : знайдіть приховані теми в колекції документів.
- Оцінка щільності : Оцініть функцію щільності ймовірності даних.
- Стиснення зображень і відео : Зменште обсяг пам’яті, необхідного для мультимедійного вмісту.
- Попередня обробка даних : допомога в завданнях попередньої обробки даних, таких як очищення даних, імпутація відсутніх значень і масштабування даних.
- Аналіз ринкового кошика : знайдіть асоціації між продуктами.
- Аналіз геномних даних : Ідентифікуйте шаблони або згрупуйте гени з подібними профілями експресії.
- Сегментація зображення : сегментуйте зображення на значущі області.
- Виявлення спільноти в соціальних мережах : Визначте спільноти або групи осіб зі схожими інтересами чи зв’язками.
- Аналіз поведінки клієнтів : розкрийте закономірності та ідеї для кращого маркетингу та рекомендацій щодо продуктів.
- Рекомендація щодо змісту : класифікуйте та позначайте тегами вміст, щоб було легше рекомендувати користувачам схожі елементи.
- Дослідницький аналіз даних (EDA) : досліджуйте дані та отримуйте уявлення перед визначенням конкретних завдань.
3. Напівконтрольоване навчання
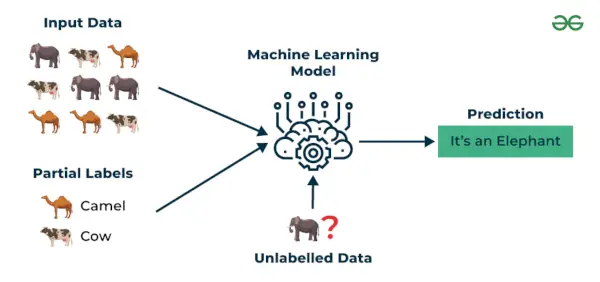
Напівконтрольоване навчання це алгоритм машинного навчання, який працює між під наглядом і без нагляду навчання, тому він використовує обидва мічені та не марковані даних. Це особливо корисно, коли отримання мічених даних є дорогим, тривалим або ресурсомістким. Цей підхід корисний, коли набір даних дорогий і займає багато часу. Напівконтрольоване навчання вибирається, коли позначені дані потребують навичок і відповідних ресурсів для навчання або навчання на них.
Ми використовуємо ці методи, коли маємо справу з даними, які трохи помічені, а решта їх значна частина не позначена. Ми можемо використовувати неконтрольовані методи для прогнозування міток, а потім передати ці мітки контрольованим методам. Ця техніка здебільшого застосовна у випадку наборів даних зображень, де зазвичай усі зображення не позначені.
Напівконтрольоване навчання
Розберемося в цьому на прикладі.
приклад : Вважайте, що ми будуємо модель мовного перекладу, позначення перекладів для кожної пари речень може потребувати ресурсів. Це дозволяє моделям навчатися з позначених і не позначених пар речень, роблячи їх більш точними. Ця техніка призвела до значного покращення якості послуг машинного перекладу.
Типи напівконтрольованих методів навчання
Існує кілька різних методів напівконтрольованого навчання, кожен зі своїми особливостями. Деякі з найпоширеніших включають:
- Напівконтрольоване навчання на основі графів: Цей підхід використовує графік для представлення зв’язків між точками даних. Потім графік використовується для поширення міток від позначених точок даних до непозначених точок даних.
- Поширення етикетки: Цей підхід ітеративно поширює мітки від позначених точок даних до непозначених точок даних на основі подібності між точками даних.
- Спільне навчання: Цей підхід тренує дві різні моделі машинного навчання на різних підмножинах непозначених даних. Потім дві моделі використовуються для позначення прогнозів одна одної.
- Самопідготовка: Цей підхід навчає модель машинного навчання на позначених даних, а потім використовує модель для прогнозування міток для непозначених даних. Потім модель перенавчається на позначених даних і прогнозованих мітках для непозначених даних.
- Генеративні змагальні мережі (GAN) : GAN – це тип алгоритму глибокого навчання, який можна використовувати для створення синтетичних даних. GAN можна використовувати для створення немаркованих даних для напівконтрольованого навчання шляхом навчання двох нейронних мереж, генератора та дискримінатора.
Переваги напівконтрольованого машинного навчання
- Це призводить до кращого узагальнення порівняно з навчання під наглядом, оскільки він приймає як позначені, так і немарковані дані.
- Може застосовуватися до широкого діапазону даних.
Недоліки напівконтрольованого машинного навчання
- Напівнаглядовий методи можуть бути більш складними для реалізації порівняно з іншими підходами.
- Це ще вимагає деяких позначені дані які не завжди можуть бути доступними або легко отримати.
- Дані без міток можуть відповідним чином вплинути на продуктивність моделі.
Застосування напівконтрольованого навчання
Ось кілька поширених застосувань напівконтрольованого навчання:
- Класифікація зображень і розпізнавання об'єктів : підвищте точність моделей, об’єднавши невеликий набір зображень із мітками з більшим набором зображень без міток.
- Обробка природної мови (NLP) : підвищте продуктивність мовних моделей і класифікаторів, об’єднавши невеликий набір текстових даних із мітками з великою кількістю тексту без міток.
- Розпізнавання мови: Підвищте точність розпізнавання мовлення, використовуючи обмежену кількість транскрибованих мовних даних і більший набір аудіо без міток.
- Рекомендаційні системи : підвищте точність персоналізованих рекомендацій, доповнивши розріджений набір взаємодій користувача з елементами (дані з мітками) великою кількістю даних про поведінку користувачів без міток.
- Охорона здоров'я та медична візуалізація : Покращте аналіз медичних зображень, використовуючи невеликий набір медичних зображень із мітками разом із більшим набором зображень без міток.
4. Підкріплення машинного навчання
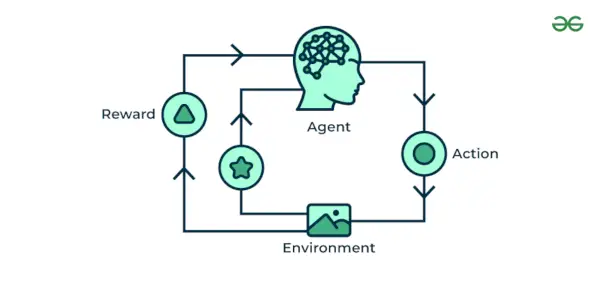
Підкріплення машинного навчання Алгоритм — це метод навчання, який взаємодіє з навколишнім середовищем, виконуючи дії та виявляючи помилки. Проби, помилки та зволікання є найбільш відповідними характеристиками навчання з підкріпленням. У цій техніці модель продовжує збільшувати свою ефективність, використовуючи зворотний зв’язок винагороди, щоб дізнатися про поведінку або шаблон. Ці алгоритми є специфічними для конкретної проблеми, напр. Google Self Driving car, AlphaGo, де бот змагається з людьми і навіть із самим собою, щоб досягати кращих і кращих результатів у Go Game. Кожного разу, коли ми подаємо дані, вони вивчають і додають дані до своїх знань, які є навчальними даними. Отже, чим більше він навчається, тим краще він отримує підготовку і, отже, досвід.
Ось деякі з найпоширеніших алгоритмів навчання з підкріпленням:
- Q-навчання: Q-навчання — це безмодельний алгоритм RL, який вивчає Q-функцію, яка відображає стани на дії. Q-функція оцінює очікувану винагороду за виконання конкретної дії в даному стані.
- SARSA (State-Action-Reward-State-Action): SARSA — це ще один безмодельний алгоритм RL, який вивчає Q-функцію. Однак, на відміну від Q-навчання, SARSA оновлює Q-функцію для дійсно виконаної дії, а не для оптимальної дії.
- Глибоке Q-навчання : Deep Q-learning — це поєднання Q-learning і deep learning. Глибоке Q-навчання використовує нейронну мережу для представлення Q-функції, що дозволяє вивчати складні зв’язки між станами та діями.
Підкріплення машинного навчання
Розберемося в цьому на прикладах.
приклад: Вважайте, що ви тренуєтеся ШІ агент грати в таку гру, як шахи. Агент вивчає різні ходи та отримує позитивний чи негативний відгук залежно від результату. Reinforcement Learning також знаходить програми, в яких вони вчаться виконувати завдання, взаємодіючи з оточенням.
Типи машинного навчання з підкріпленням
Існує два основних типи навчання з підкріпленням:
Позитивне підкріплення
- Винагороджує агента за виконання бажаної дії.
- Заохочує агента повторити поведінку.
- Приклади: давати ласощі собаці за те, що він сидів, отримувати очко в грі за правильну відповідь.
Негативне підкріплення
- Усуває небажаний стимул для стимулювання бажаної поведінки.
- Перешкоджає агенту повторювати поведінку.
- Приклади: вимкнення гучного звукового сигналу під час натискання важеля, уникнення штрафу шляхом виконання завдання.
Переваги машинного навчання з підкріпленням
- Він має автономне прийняття рішень, яке добре підходить для завдань і може навчитися приймати послідовність рішень, як-от робототехніка та ігри.
- Цій техніці віддають перевагу для досягнення довгострокових результатів, яких дуже важко досягти.
- Він використовується для вирішення складних завдань, які неможливо вирішити звичайними методами.
Недоліки машинного навчання з підкріпленням
- Навчання Reinforcement Агенти навчання можуть бути обчислювально дорогими та трудомісткими.
- Навчання з підкріпленням не краще, ніж розв’язування простих задач.
- Для цього потрібно багато даних і багато обчислень, що робить його непрактичним і дорогим.
Застосування машинного навчання з підкріпленням
Ось кілька застосувань навчання з підкріпленням:
- Гра в гру : RL може навчити агентів грати в ігри, навіть складні.
- Робототехніка : RL може навчити роботів виконувати завдання автономно.
- Автономні транспортні засоби : RL може допомогти безпілотним автомобілям орієнтуватися та приймати рішення.
- Рекомендаційні системи : RL може покращити алгоритми рекомендацій, вивчаючи налаштування користувача.
- Охорона здоров'я : RL можна використовувати для оптимізації планів лікування та відкриття ліків.
- Обробка природної мови (NLP) : RL можна використовувати в діалогових системах і чат-ботах.
- Фінанси та торгівля : RL можна використовувати для алгоритмічної торгівлі.
- Управління ланцюгом постачання та запасами : RL можна використовувати для оптимізації операцій ланцюга поставок.
- Енергетичний менеджмент : RL можна використовувати для оптимізації споживання енергії.
- Ігри зі штучним інтелектом : RL можна використовувати для створення більш розумних і адаптивних NPC у відеоіграх.
- Адаптивні персональні помічники : RL можна використовувати для покращення персональних помічників.
- Віртуальна реальність (VR) і доповнена реальність (AR): RL можна використовувати для створення ефекту занурення та інтерактивного досвіду.
- Промисловий контроль : RL можна використовувати для оптимізації промислових процесів.
- Освіта : РЛ можна використовувати для створення адаптивних систем навчання.
- Сільське господарство : РЛ можна використовувати для оптимізації сільськогосподарських робіт.
Обов'язково перевірте, наша докладна стаття про : Алгоритми машинного навчання
Висновок
Підсумовуючи, кожен тип машинного навчання служить власним цілям і сприяє загальній ролі в розробці розширених можливостей прогнозування даних, і він має потенціал змінити різні галузі, як-от Data Science . Це допомагає впоратися з масивним виробництвом даних і керуванням наборами даних.
Типи машинного навчання – поширені запитання
1. З якими проблемами стикаються під час навчання під контролем?
Деякі з проблем, з якими стикаються під час навчання під наглядом, в основному включають усунення дисбалансу класів, високоякісні дані з мітками та уникнення надмірного оснащення, коли моделі погано працюють з даними в реальному часі.
2. Де ми можемо застосувати контрольоване навчання?
Контрольоване навчання зазвичай використовується для таких завдань, як аналіз спаму, розпізнавання зображень і аналіз настроїв.
3. Як виглядає майбутнє машинного навчання?
Машинне навчання як перспектива майбутнього може працювати в таких сферах, як аналіз погоди чи клімату, системи охорони здоров’я та автономне моделювання.
4. Які є різні типи машинного навчання?
Існує три основних типи машинного навчання:
- Контрольоване навчання
- Навчання без контролю
- Навчання з підкріпленням
5. Які найпоширеніші алгоритми машинного навчання?
Деякі з найпоширеніших алгоритмів машинного навчання включають:
- Лінійна регресія
- Логістична регресія
- Машини підтримки векторів (SVM)
- K-найближчі сусіди (KNN)
- Дерева рішень
- Випадкові ліси
- Штучні нейронні мережі