У реальному світі не всі дані, з якими ми працюємо, мають цільову змінну. Такі дані не можна аналізувати за допомогою алгоритмів навчання під наглядом. Нам потрібна допомога неконтрольованих алгоритмів. Одним із найпопулярніших типів аналізу під неконтрольованим навчанням є сегментація клієнтів для цільової реклами або в медичній візуалізації для пошуку невідомих або нових заражених областей і багато інших випадків використання, які ми обговоримо далі в цій статті.
Зміст
розрахунок терміну перебування в excel
- Що таке кластеризація?
- Типи кластеризації
- Використання кластеризації
- Типи алгоритмів кластеризації
- Застосування кластеризації в різних областях:
- Часті запитання (FAQ) щодо кластеризації
Що таке кластеризація?
Завдання групування точок даних на основі їх схожості одна з одною називається кластеризацією або кластерним аналізом. Цей метод визначено під галуззю Навчання без контролю , яка спрямована на отримання інформації з немаркованих точок даних, тобто на відміну від навчання під наглядом у нас немає цільової змінної.
Метою кластеризації є формування груп однорідних точок даних із різнорідного набору даних. Він оцінює подібність на основі таких показників, як евклідова відстань, косинусова подібність, манхеттенська відстань тощо, а потім групує точки з найвищим показником подібності.
Наприклад, на наведеному нижче графіку ми чітко бачимо, що на основі відстані утворюються 3 круглі кластери.
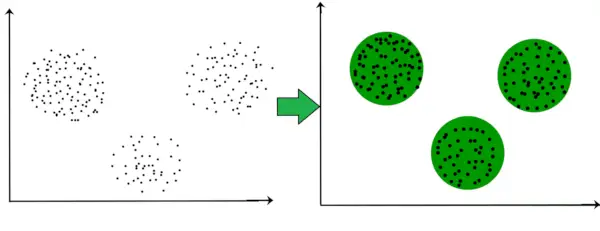
Тепер необов’язково, щоб сформовані кластери мали круглу форму. Форма грон може бути довільною. Існує багато алгоритмів, які добре працюють із виявленням кластерів довільної форми.
Наприклад, на наведеному нижче графіку ми бачимо, що утворені кластери не мають круглої форми.

Типи кластеризації
Загалом, існує 2 типи кластеризації, які можна виконати для групування схожих точок даних:
- Жорстка кластеризація: У цьому типі кластеризації кожна точка даних належить кластеру повністю чи ні. Наприклад, припустимо, що є 4 точки даних, і ми повинні згрупувати їх у 2 кластери. Отже, кожна точка даних належатиме до кластера 1 або кластера 2.
| Точки даних | Кластери |
|---|---|
| А | C1 |
| Б | C2 |
| C | C2 |
| Д | C1 |
- М'яка кластеризація: У цьому типі кластеризації замість того, щоб призначати кожну точку даних в окремий кластер, оцінюється ймовірність того, що ця точка є цим кластером. Наприклад, припустимо, що є 4 точки даних, і ми повинні згрупувати їх у 2 кластери. Отже, ми будемо оцінювати ймовірність того, що точка даних належить до обох кластерів. Ця ймовірність обчислюється для всіх точок даних.
| Точки даних | Імовірність C1 | Імовірність С2 |
| А | 0,91 | 0,09 |
| Б | 0,3 | 0,7 |
| C | 0,17 | 0,83 |
| Д | 1 | 0 |
Використання кластеризації
Перш ніж почати з типів алгоритмів кластеризації, ми розглянемо випадки використання алгоритмів кластеризації. Алгоритми кластеризації в основному використовуються для:
- Сегментація ринку – Компанії використовують кластеризацію для групування своїх клієнтів і використовують цільову рекламу для залучення більшої аудиторії.
- Аналіз соціальних мереж – Сайти соціальних медіа використовують ваші дані, щоб зрозуміти вашу поведінку в Інтернеті та надати вам цільові рекомендації друзів або рекомендації щодо вмісту.
- Медична візуалізація – лікарі використовують кластеризацію, щоб знайти уражені ділянки на діагностичних зображеннях, таких як рентгенівські знімки.
- Виявлення аномалії – Для виявлення викидів у потоці набору даних у реальному часі або прогнозування шахрайських транзакцій ми можемо використовувати кластеризацію для їх виявлення.
- Спростіть роботу з великими наборами даних – кожному кластеру надається ідентифікатор кластера після завершення кластеризації. Тепер ви можете скоротити весь набір функцій до ідентифікатора кластера. Кластеризація ефективна, коли вона може представляти складний випадок із простим ідентифікатором кластера. Використовуючи той самий принцип, кластеризація даних може спростити складні набори даних.
Існує багато інших варіантів використання кластеризації, але є деякі з основних і поширених випадків використання кластеризації. Надалі ми будемо обговорювати алгоритми кластеризації, які допоможуть вам виконувати вищезазначені завдання.
Типи алгоритмів кластеризації
На поверхневому рівні кластеризація допомагає аналізувати неструктуровані дані. Побудова графіків, найкоротша відстань і щільність точок даних – це лише деякі з елементів, які впливають на формування кластера. Кластеризація — це процес визначення того, наскільки пов’язані об’єкти на основі метрики, яка називається мірою подібності. Показники подібності легше знайти в менших наборах ознак. Зі збільшенням кількості ознак стає важче створити показники подібності. Залежно від типу алгоритму кластеризації, який використовується в інтелектуальному аналізі даних, використовується кілька методів для групування даних із наборів даних. У цій частині описані методи кластеризації. Різні типи алгоритмів кластеризації:
- Кластеризація на основі центроїда (методи розбиття)
- Кластеризація на основі щільності (методи на основі моделі)
- Кластеризація на основі підключення (ієрархічна кластеризація)
- Кластеризація на основі розподілу
Ми коротко розглянемо кожен із цих типів.
1. Методи поділу є найпростішими алгоритмами кластеризації. Вони групують точки даних на основі їх близькості. Як правило, мірою подібності, обраною для цих алгоритмів, є евклідова відстань, відстань Манхеттена або відстань Мінковського. Набори даних розділені на заздалегідь визначену кількість кластерів, і на кожен кластер посилається вектор значень. У порівнянні з векторним значенням змінна вхідних даних не показує різниці та приєднується до кластера.
Основним недоліком цих алгоритмів є вимога, щоб ми встановили кількість кластерів, k, або інтуїтивно, або науково (за допомогою методу Elbow), перш ніж будь-яка система машинного навчання кластеризації почне розподіляти точки даних. Незважаючи на це, це все ще найпопулярніший вид кластеризації. К-означає і К-медоїди кластеризація є деякими прикладами цього типу кластеризації.
2. Кластеризація на основі щільності (методи на основі моделі)
Кластеризація на основі щільності, метод на основі моделі, знаходить групи на основі щільності точок даних. На відміну від кластеризації на основі центроїда, яка вимагає попереднього визначення кількості кластерів і чутливості до ініціалізації, кластеризація на основі щільності визначає кількість кластерів автоматично та менш чутлива до початкових позицій. Вони чудово справляються з кластерами різних розмірів і форм, що робить їх ідеальними для наборів даних із кластерами неправильної форми або перекриттям. Ці методи керують як щільними, так і розрідженими областями даних, зосереджуючись на локальній щільності, і можуть розрізняти кластери з різними морфологіями.
Навпаки, групування на основі центроїда, як і k-середні, має проблеми з пошуком кластерів довільної форми. Через попередньо встановлену кількість вимог до кластерів і надзвичайну чутливість до початкового розташування центроїдів результати можуть відрізнятися. Крім того, тенденція підходів, заснованих на центроїді, створювати сферичні або опуклі кластери, обмежує їхню здатність працювати зі складними кластерами або кластерами неправильної форми. Підсумовуючи, кластеризація на основі щільності долає недоліки методів, заснованих на центроїді, шляхом автономного вибору розмірів кластерів, стійкості до ініціалізації та успішного захоплення кластерів різних розмірів і форм. Найпопулярнішим алгоритмом кластеризації на основі щільності є DBSCAN .
3. Кластеризація на основі підключення (ієрархічна кластеризація)
Метод об’єднання пов’язаних точок даних в ієрархічні кластери називається ієрархічною кластеризацією. Кожна точка даних спочатку враховується як окремий кластер, який згодом поєднується з кластерами, які є найбільш схожими, щоб утворити один великий кластер, який містить усі точки даних.
Подумайте, як ви можете організувати колекцію предметів на основі того, наскільки вони схожі. Кожен об’єкт починається як власний кластер у основі дерева при використанні ієрархічної кластеризації, яка створює дендрограму, деревоподібну структуру. Найближчі пари кластерів потім об’єднуються у більші кластери після того, як алгоритм досліджує, наскільки об’єкти схожі один на одного. Коли кожен об’єкт знаходиться в одному кластері у верхній частині дерева, процес об’єднання завершився. Дослідження різних рівнів деталізації — одна з цікавих речей ієрархічної кластеризації. Щоб отримати задану кількість кластерів, ви можете вирізати дендрограма на певній висоті. Чим більше схожі два об’єкти в кластері, тим ближче вони. Це можна порівняти з класифікацією предметів відповідно до їхніх генеалогічних дерев, де найближчі родичі згруповані разом, а ширші гілки означають більш загальні зв’язки. Існує 2 підходи до ієрархічної кластеризації:
- Роздільна кластеризація : Він дотримується підходу зверху вниз, тут ми вважаємо всі точки даних частиною одного великого кластера, а потім цей кластер ділимо на менші групи.
- Агломеративна кластеризація : Він дотримується підходу «знизу вгору», тут ми вважаємо всі точки даних частиною окремих кластерів, а потім ці кластери об’єднуються разом, щоб створити один великий кластер з усіма точками даних.
4. Кластеризація на основі розподілу
Використовуючи кластеризацію на основі розподілу, точки даних генеруються та організовуються відповідно до їхньої схильності потрапляти до того самого розподілу ймовірностей (наприклад, Гаусса, біноміального чи іншого) в межах даних. Елементи даних групуються за допомогою ймовірнісного розподілу, який базується на статистичних розподілах. Включено об’єкти даних, які мають більшу ймовірність бути в кластері. Точка даних з меншою ймовірністю буде включена в кластер, чим далі вона знаходиться від центральної точки кластера, яка існує в кожному кластері.
Помітним недоліком підходів, заснованих на щільності та межах, є необхідність апріорного визначення кластерів для деяких алгоритмів, і, насамперед, визначення форми кластера для основної маси алгоритмів. Має бути вибрано принаймні одне налаштування або гіперпараметр, і хоча це має бути просто, неправильне налаштування може мати непередбачені наслідки. Кластеризація на основі розподілу має певну перевагу перед підходами кластеризації на основі близькості та центроїда з точки зору гнучкості, точності та структури кластера. Ключове питання полягає в тому, щоб уникнути переобладнання , багато методів кластеризації працюють лише зі змодельованими або виготовленими даними або коли основна частина точок даних належать до попередньо встановленого розподілу. Найпопулярнішим алгоритмом кластеризації на основі розподілу є Модель суміші Гауса .
Застосування кластеризації в різних областях:
- маркетинг: Його можна використовувати для характеристики та виявлення сегментів клієнтів у маркетингових цілях.
- Біологія: Його можна використовувати для класифікації різних видів рослин і тварин.
- Бібліотеки: Він використовується для групування різних книг на основі тем та інформації.
- страхування: Він використовується для визнання клієнтів, їх політики та виявлення шахрайства.
- Містопланування: Він використовується для створення груп будинків і вивчення їх цінностей на основі їхнього географічного положення та інших чинників.
- Дослідження землетрусів: Вивчивши райони, які постраждали від землетрусу, ми можемо визначити небезпечні зони.
- Обробка зображення : Кластеризацію можна використовувати для групування подібних зображень разом, класифікації зображень на основі вмісту та виявлення шаблонів у даних зображення.
- Генетика: Кластеризація використовується для групування генів, які мають подібні шаблони експресії, і ідентифікації генних мереж, які працюють разом у біологічних процесах.
- Фінанси: Кластеризація використовується для ідентифікації ринкових сегментів на основі поведінки клієнтів, визначення закономірностей у даних фондового ринку та аналізу ризику в інвестиційних портфелях.
- Обслуговування клієнтів: Кластеризація використовується для групування запитів і скарг клієнтів у категорії, виявлення спільних проблем і розробки цільових рішень.
- Виробництво : Кластеризація використовується для групування схожих продуктів, оптимізації виробничих процесів і виявлення дефектів у виробничих процесах.
- Медичний діагноз: Кластеризація використовується для групування пацієнтів зі схожими симптомами або захворюваннями, що допомагає встановити точний діагноз і визначити ефективне лікування.
- Виявлення шахрайства: Кластеризація використовується для виявлення підозрілих моделей або аномалій у фінансових операціях, що може допомогти у виявленні шахрайства чи інших фінансових злочинів.
- Аналіз трафіку: Кластеризація використовується для групування подібних шаблонів даних про дорожній рух, таких як години пік, маршрути та швидкості, що може допомогти в покращенні транспортного планування та інфраструктури.
- Аналіз соціальних мереж: Кластеризація використовується для визначення спільнот або груп у соціальних мережах, що може допомогти зрозуміти соціальну поведінку, вплив і тенденції.
- Кібербезпека: Кластеризація використовується для групування подібних моделей мережевого трафіку або поведінки системи, що може допомогти у виявленні та запобіганні кібератакам.
- Аналіз клімату: Кластеризація використовується для групування подібних моделей кліматичних даних, таких як температура, опади та вітер, які можуть допомогти зрозуміти зміну клімату та її вплив на навколишнє середовище.
- Спортивний аналіз: Кластеризація використовується для групування подібних шаблонів даних про ефективність гравців або команд, що може допомогти в аналізі сильних і слабких сторін гравців або команди та прийнятті стратегічних рішень.
- Аналіз злочинності: Кластеризація використовується для групування схожих шаблонів даних про злочини, таких як місцезнаходження, час і тип, що може допомогти у визначенні гарячих точок злочинності, прогнозуванні майбутніх тенденцій злочинності та вдосконаленні стратегій запобігання злочинності.
Висновок
У цій статті ми обговорили кластеризацію, її типи та програми в реальному світі. У неконтрольованому навчанні є багато іншого, і кластерний аналіз є лише першим кроком. Ця стаття може допомогти вам розпочати роботу з алгоритмами кластеризації та отримати новий проект, який можна додати до вашого портфоліо.
Часті запитання (FAQ) щодо кластеризації
Q. Який найкращий метод кластеризації?
10 найкращих алгоритмів кластеризації:
- K-означає кластеризацію
- Ієрархічна кластеризація
- DBSCAN (просторова кластеризація програм на основі щільності з шумом)
- Моделі суміші Гауса (GMM)
- Агломеративна кластеризація
- Спектральна кластеризація
- Кластеризація середнього зсуву
- Поширення афінності
- ОПТИКА (впорядкування точок для визначення структури кластеризації)
- Birch (збалансоване ітераційне скорочення та кластеризація за допомогою ієрархій)
З. Яка різниця між кластеризацією та класифікацією?
Основна відмінність між кластеризацією та класифікацією полягає в тому, що класифікація — це контрольований алгоритм навчання, а кластеризація — неконтрольований алгоритм навчання. Тобто ми застосовуємо кластеризацію до тих наборів даних, які не мають цільової змінної.
З. Які переваги кластерного аналізу?
Дані можна організовувати у значущі групи за допомогою сильного аналітичного інструменту кластерного аналізу. Ви можете використовувати його для точного визначення сегментів, пошуку прихованих закономірностей і покращення рішень.
Q. Який метод кластеризації є найшвидшим?
Кластеризація K-середніх часто вважається найшвидшим методом кластеризації через його простоту та обчислювальну ефективність. Він ітеративно призначає точки даних найближчому центроїду кластера, що робить його придатним для великих наборів даних із низькою розмірністю та помірною кількістю кластерів.
З. Які обмеження кластеризації?
Обмеження кластеризації включають чутливість до початкових умов, залежність від вибору параметрів, труднощі у визначенні оптимальної кількості кластерів і проблеми з обробкою даних великої розмірності або шуму.
Q. Від чого залежить якість результату кластеризації?
Якість результатів кластеризації залежить від таких факторів, як вибір алгоритму, показник відстані, кількість кластерів, метод ініціалізації, методи попередньої обробки даних, показники оцінки кластера та знання предметної області. Ці елементи разом впливають на ефективність і точність результату кластеризації.