Перш ніж розглядати відмінності між BFS і DFS, ми повинні знати про BFS і DFS окремо.
Що таке BFS?
BFS виступає за Пошук спочатку вшир . Він також відомий як обхід порядку рівня . Структура даних Queue використовується для обходу пошуку в ширину. Коли ми використовуємо алгоритм BFS для обходу в графі, ми можемо розглядати будь-який вузол як кореневий вузол.
Давайте розглянемо наведений нижче графік для обходу пошуку в ширину.
scan.next java
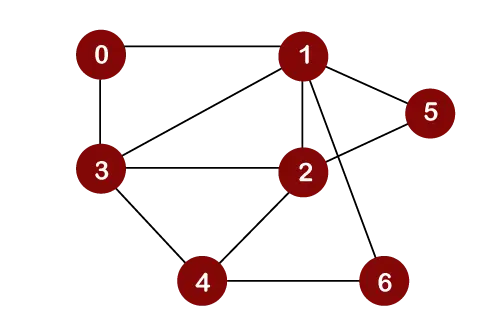
Припустимо, ми вважаємо вузол 0 кореневим вузлом. Таким чином, обхід буде розпочато з вузла 0.

Після видалення вузла 0 із черги він друкується та позначається як a відвіданий вузол.
Після того, як вузол 0 буде видалено з черги, сусідні вузли вузла 0 будуть вставлені в чергу, як показано нижче:

Тепер вузол 1 буде видалено з черги; він друкується та позначається як відвіданий вузол
Після того, як вузол 1 буде видалено з черги, усі суміжні вузли вузла 1 будуть додані до черги. Сусідніми вузлами вузла 1 є 0, 3, 2, 6 і 5. Але ми повинні вставити в чергу лише невідвідані вузли. Оскільки вузли 3, 2, 6 і 5 є невідвіданими; тому ці вузли будуть додані в чергу, як показано нижче:

Наступний вузол 3 у черзі. Отже, вузол 3 буде видалено з черги, він буде надрукований і позначений як відвіданий, як показано нижче:

Після того, як вузол 3 буде видалено з черги, усі суміжні вузли вузла 3, крім відвіданих вузлів, будуть додані до черги. Сусідніми вузлами вузла 3 є 0, 1, 2 і 4. Оскільки вузли 0, 1 уже відвідано, а вузол 2 присутній у черзі; отже, нам потрібно вставити лише вузол 4 у чергу.
перейменування каталогу linux

Тепер наступним вузлом у черзі є 2. Отже, 2 буде видалено з черги. Він друкується та позначається як відвіданий, як показано нижче:

Після того, як вузол 2 буде видалено з черги, усі суміжні вузли вузла 2, крім відвіданих вузлів, будуть додані до черги. Сусідніми вузлами вузла 2 є 1, 3, 5, 6 і 4. Оскільки вузли 1 і 3 вже були відвідані, а 4, 5, 6 вже додано в чергу; отже, нам не потрібно вставляти вузол у чергу.
Наступний елемент – 5. Отже, 5 буде видалено з черги. Він друкується та позначається як відвіданий, як показано нижче:

Після того, як вузол 5 буде видалено з черги, усі суміжні вузли вузла 5, крім відвіданих вузлів, будуть додані до черги. Сусідні вузли вузла 5 — це 1 і 2. Оскільки обидва вузли вже були відвідані; отже, немає вершини, яку можна вставити в чергу.
Наступний вузол 6. Отже, 6 буде видалено з черги. Він друкується та позначається як відвіданий, як показано нижче:

Після того, як вузол 6 буде видалено з черги, усі суміжні вузли вузла 6, крім відвіданих вузлів, будуть додані до черги. Сусідніми вузлами вузла 6 є 1 і 4. Оскільки вузол 1 уже відвідано, а вузол 4 уже додано в чергу; отже, немає вершини для вставлення в чергу.
Наступним елементом у черзі є 4. Отже, 4 буде видалено з черги. Він друкується та позначається як відвіданий.
Після того, як вузол 4 буде видалено з черги, усі суміжні вузли вузла 4, крім відвіданих вузлів, будуть додані до черги. Сусідніми вузлами вузла 4 є 3, 2 і 6. Оскільки всі сусідні вузли вже відвідано; отже, немає жодної вершини для вставлення в чергу.
анаконда проти змії-пітона
Що таке DFS?
ДФС розшифровується як Depth First Search. У обході DFS використовується стекова структура даних, яка працює за принципом LIFO (Last In First Out). У DFS обхід можна розпочати з будь-якого вузла, або ми можемо сказати, що будь-який вузол можна вважати кореневим вузлом, доки кореневий вузол не згадується в задачі.
У випадку BFS, елемент, який видаляється з черги, сусідні вузли видаленого вузла додаються до черги. На відміну від цього, у DFS, елемент, який видаляється зі стеку, тоді до стека додається лише один суміжний вузол видаленого вузла.
Давайте розглянемо наведений нижче графік для обходу Depth First Search.

Розглядайте вузол 0 як кореневий вузол.
Спочатку ми вставляємо елемент 0 у стек, як показано нижче:
css підкреслений текст

Вузол 0 має два суміжних вузла, тобто 1 і 3. Тепер ми можемо взяти лише один суміжний вузол, або 1, або 3, для обходу. Припустимо, ми розглядаємо вузол 1; отже, 1 вставляється в стек і друкується, як показано нижче:

Тепер ми розглянемо суміжні вершини вузла 1. Невідвіданими сусідніми вершинами вузла 1 є 3, 2, 5 і 6. Ми можемо розглянути будь-яку з цих чотирьох вершин. Припустимо, ми беремо вузол 3 і вставляємо його в стек, як показано нижче:

Розглянемо невідвідані суміжні вершини вузла 3. Невідвідані суміжні вершини вузла 3 — це 2 і 4. Ми можемо взяти будь-яку з вершин, тобто 2 або 4. Припустимо, ми беремо вершину 2 і вставляємо її в стек, як показано нижче:

Невідвідані суміжні вершини вузла 2 — це 5 і 4. Ми можемо вибрати будь-яку з вершин, тобто 5 або 4. Припустимо, ми беремо вершину 4 і вставляємо її в стек, як показано нижче:

Тепер ми розглянемо невідвідані суміжні вершини вузла 4. Невідвідана суміжна вершина вузла 4 є вузлом 6. Тому елемент 6 вставляється в стек, як показано нижче:

Після вставки елемента 6 у стек ми подивимося на невідвідані суміжні вершини вузла 6. Оскільки немає невідвіданих суміжних вершин вузла 6, ми не можемо перейти за межі вузла 6. У цьому випадку ми виконаємо відкат . Найвищий елемент, тобто 6, буде висунуто зі стеку, як показано нижче:


Найвищий елемент у стеку — це 4. Оскільки від вузла 4 не залишилося невідвіданих суміжних вершин; отже, вузол 4 висувається зі стеку, як показано нижче:
усі великі літери ярлик excel


Наступний найвищий елемент у стеку – 2. Тепер ми розглянемо невідвідані сусідні вершини вузла 2. Оскільки залишився лише один невідвіданий вузол, тобто 5, то вузол 5 буде поміщено в стек вище 2 і буде надруковано як показано нижче:

Тепер ми перевіримо суміжні вершини вузла 5, які ще не відвідані. Оскільки не залишилося жодної вершини, яку потрібно відвідати, ми витягуємо елемент 5 зі стеку, як показано нижче:

Ми не можемо рухатися далі на 5, тому нам потрібно виконати зворотний шлях. Під час зворотного відстеження верхній елемент буде висунуто зі стеку. Найвищий елемент — це 5, який буде висунуто зі стеку, і ми повернемося до вузла 2, як показано нижче:

Тепер ми перевіримо невідвідані суміжні вершини вузла 2. Оскільки не залишилося жодної суміжної вершини, яку потрібно відвідати, ми виконуємо зворотне відстеження. У зворотному відстеженні верхній елемент, тобто 2, буде висунуто зі стеку, і ми повернемося до вузла 3, як показано нижче:


Тепер ми перевіримо невідвідані суміжні вершини вузла 3. Оскільки не залишилося жодної суміжної вершини, яку потрібно відвідати, ми виконуємо зворотне відстеження. У зворотному відстеженні верхній елемент, тобто 3, буде вискочити зі стеку, і ми повернемося до вузла 1, як показано нижче:


Після відкриття елемента 3 ми перевіримо невідвідані суміжні вершини вузла 1. Оскільки не залишилося жодної вершини, яку потрібно відвідати; отже, буде виконано зворотне відстеження. У зворотному відстеженні верхній елемент, тобто 1, буде висунуто зі стеку, і ми повернемося до вузла 0, як показано нижче:


Ми перевіримо суміжні вершини вузла 0, які ще не відвідані. Оскільки не залишилося жодної суміжної вершини, яку потрібно відвідати, ми виконуємо відстеження. У цьому випадку лише один елемент, тобто 0, що залишився в стеку, буде винесено зі стеку, як показано нижче:

Як ми бачимо на малюнку вище, стек порожній. Отже, ми повинні зупинити обхід DFS тут, а елементи, які друкуються, є результатом обходу DFS.
Відмінності між BFS і DFS
Нижче наведено відмінності між BFS і DFS:
| BFS | ДФС | |
|---|---|---|
| Повна форма | BFS розшифровується як Breadth First Search. | DFS означає Depth First Search. |
| Техніка | Це техніка на основі вершин для пошуку найкоротшого шляху в графі. | Це техніка, заснована на ребрах, оскільки спочатку досліджуються вершини вздовж краю від початкового до кінцевого вузла. |
| Визначення | BFS — це техніка обходу, за якої спочатку досліджуються всі вузли одного рівня, а потім ми переходимо до наступного рівня. | DFS також є технікою обходу, у якій обхід починається з кореневого вузла та досліджується вузли настільки далеко, наскільки це можливо, поки ми не досягнемо вузла, який не має невідвіданих сусідніх вузлів. |
| Структура даних | Структура даних черги використовується для обходу BFS. | Структура даних стека використовується для обходу BFS. |
| Відстеження назад | BFS не використовує концепцію зворотного відстеження. | DFS використовує зворотне відстеження для проходження всіх невідвіданих вузлів. |
| Кількість ребер | BFS знаходить найкоротший шлях із мінімальною кількістю ребер для проходження від вихідної до кінцевої вершини. | У DFS потрібна більша кількість ребер для переходу від вихідної вершини до кінцевої вершини. |
| Оптимальність | Обхід BFS оптимальний для тих вершин, які потрібно шукати ближче до вихідної вершини. | Обхід DFS оптимальний для тих графів, у яких розв’язки віддалені від вихідної вершини. |
| швидкість | BFS повільніше, ніж DFS. | DFS швидше, ніж BFS. |
| Придатність для дерева рішень | Він не підходить для дерева рішень, оскільки спочатку вимагає вивчення всіх сусідніх вузлів. | Він підходить для дерева рішень. На основі рішення досліджує всі шляхи. Коли мета знайдена, вона припиняє свій обхід. |
| Ефективна пам'ять | Це не ефективне використання пам'яті, оскільки вимагає більше пам'яті, ніж DFS. | Він ефективний, оскільки потребує менше пам’яті, ніж BFS. |