У цій статті ми обговоримо алгоритм DFS у структурі даних. Це рекурсивний алгоритм для пошуку всіх вершин структури даних дерева або графа. Алгоритм пошуку в глибину (DFS) починається з початкового вузла графа G і йде далі, доки ми не знайдемо цільовий вузол або вузол без дітей.
Через рекурсивну природу структуру даних стека можна використовувати для реалізації алгоритму DFS. Процес впровадження DFS подібний до алгоритму BFS.
Покроковий процес реалізації обходу DFS наводиться так:
- Спочатку створіть стек із загальною кількістю вершин у графі.
- Тепер виберіть будь-яку вершину як початкову точку обходу та помістіть цю вершину в стек.
- Після цього посуньте невідвідану вершину (сусідню з вершиною на вершині стека) на вершину стека.
- Тепер повторіть кроки 3 і 4, доки не залишиться жодної вершини, яку можна відвідати з вершини на вершині стека.
- Якщо не залишилося жодної вершини, поверніться назад і витягніть вершину зі стеку.
- Повторюйте кроки 2, 3 і 4, доки стек не буде порожнім.
Застосування алгоритму DFS
Додатки використання алгоритму DFS наведені наступним чином -
- Для реалізації топологічного сортування можна використовувати алгоритм DFS.
- Його можна використовувати для пошуку шляхів між двома вершинами.
- Його також можна використовувати для виявлення циклів на графіку.
- Алгоритм DFS також використовується для головоломок з одним рішенням.
- DFS використовується для визначення, чи є граф дводольним чи ні.
Алгоритм
Крок 1: SET STATUS = 1 (стан готовності) для кожного вузла в G
10 мл в унціях
крок 2: Помістіть початковий вузол A у стек і встановіть його STATUS = 2 (стан очікування)
крок 3: Повторюйте кроки 4 і 5, доки СТЕК не буде порожнім
крок 4: Витягніть верхній вузол N. Обробіть його та встановіть йому СТАТУС = 3 (оброблений стан)
крок 5: Надішліть у стек усіх сусідів N, які перебувають у стані готовності (чий STATUS = 1) і встановіть для них STATUS = 2 (стан очікування)
[КІНЕЦЬ ЦИКЛУ]
Крок 6: ВИХІД
найкращі машини в світі
Псевдокод
DFS(G,v) ( v is the vertex where the search starts ) Stack S := {}; ( start with an empty stack ) for each vertex u, set visited[u] := false; push S, v; while (S is not empty) do u := pop S; if (not visited[u]) then visited[u] := true; for each unvisited neighbour w of uu push S, w; end if end while END DFS() Приклад алгоритму DFS
Тепер давайте зрозуміємо роботу алгоритму DFS на прикладі. У наведеному нижче прикладі орієнтований граф має 7 вершин.
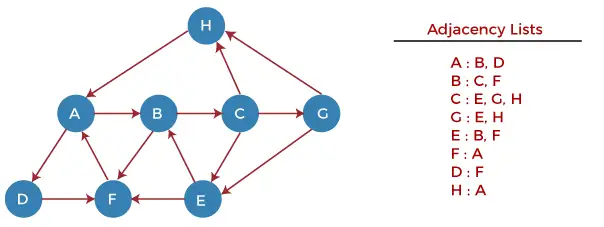
Тепер давайте почнемо розглядати графік, починаючи з Node H.
Крок 1 - Спочатку натисніть H на стек.
приклади операційної системи
STACK: H
Крок 2 - Вийміть верхній елемент зі стеку, наприклад H, і надрукуйте його. Тепер виштовхніть усіх сусідів H у стек, які перебувають у стані готовності.
Print: H]STACK: A
Крок 3 - Вийміть верхній елемент зі стеку, тобто A, і надрукуйте його. Тепер виштовхніть усіх сусідів A до стеку, які перебувають у стані готовності.
Print: A STACK: B, D
Крок 4 - Вийміть верхній елемент зі стеку, тобто D, і надрукуйте його. Тепер виштовхніть усіх сусідів D у стек, які перебувають у стані готовності.
Print: D STACK: B, F
Крок 5 - Вийміть верхній елемент зі стеку, наприклад F, і надрукуйте його. Тепер виштовхніть усіх сусідів F у стек, які перебувають у стані готовності.
Print: F STACK: B
Крок 6 - Вийміть верхній елемент зі стеку, тобто B, і надрукуйте його. Тепер виштовхніть усіх сусідів B у стек, які перебувають у стані готовності.
Print: B STACK: C
Крок 7 - Вийміть верхній елемент зі стеку, тобто C, і надрукуйте його. Тепер виштовхніть усіх сусідів C у стек, які перебувають у стані готовності.
sql server pivot
Print: C STACK: E, G
Крок 8 - POP верхній елемент зі стеку, тобто G, і PUSH усіх сусідів G у стек, які знаходяться в стані готовності.
Print: G STACK: E
Крок 9 - POP верхній елемент зі стеку, тобто E, і PUSH усіх сусідів E на стек, які знаходяться в стані готовності.
Print: E STACK:
Тепер усі вузли графа пройдено, і стек порожній.
Складність алгоритму пошуку в глибину
Часова складність алгоритму DFS становить O(V+E) , де V — кількість вершин, а E — кількість ребер у графі.
Просторова складність алгоритму DFS дорівнює O(V).
Реалізація алгоритму DFS
Тепер давайте подивимося реалізацію алгоритму DFS в Java.
У цьому прикладі графік, який ми використовуємо для демонстрації коду, подано так:

/*A sample java program to implement the DFS algorithm*/ import java.util.*; class DFSTraversal { private LinkedList adj[]; /*adjacency list representation*/ private boolean visited[]; /* Creation of the graph */ DFSTraversal(int V) /*'V' is the number of vertices in the graph*/ { adj = new LinkedList[V]; visited = new boolean[V]; for (int i = 0; i <v; i++) adj[i]="new" linkedlist(); } * adding an edge to the graph void insertedge(int src, int dest) { adj[src].add(dest); dfs(int vertex) visited[vertex]="true;" *mark current node as visited* system.out.print(vertex + ' '); iterator it="adj[vertex].listIterator();" while (it.hasnext()) n="it.next();" if (!visited[n]) dfs(n); public static main(string args[]) dfstraversal dfstraversal(8); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, system.out.println('depth first traversal for is:'); graph.dfs(0); < pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/28/dfs-algorithm-3.webp" alt="DFS algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the depth-first search technique, its example, complexity, and implementation in the java programming language. Along with that, we have also seen the applications of the depth-first search algorithm.</p> <p>So, that's all about the article. Hope it will be helpful and informative to you.</p> <hr></v;>