Один важливий аспект Машинне навчання є оцінка моделі. Вам потрібен певний механізм для оцінки вашої моделі. Саме тут ці показники продуктивності входять у картину, вони дають нам уявлення про те, наскільки хороша модель. Якщо ви знайомі з деякими основами Машинне навчання тоді ви, мабуть, стикалися з деякими з цих показників, як точність, точність, відкликання, auc-roc тощо, які зазвичай використовуються для класифікаційних завдань. У цій статті ми детально дослідимо один такий показник, який є кривою AUC-ROC.
Зміст
- Що таке крива AUC-ROC?
- Ключові терміни, що використовуються в кривих AUC і ROC
- Зв'язок між чутливістю, специфічністю, FPR і порогом.
- Як працює AUC-ROC?
- Коли ми повинні використовувати метрику оцінки AUC-ROC?
- Припущення про продуктивність моделі
- Розуміння кривої AUC-ROC
- Реалізація з використанням двох різних моделей
- Як використовувати ROC-AUC для багатокласової моделі?
- Поширені запитання щодо кривої AUC ROC у машинному навчанні
Що таке крива AUC-ROC?
Крива AUC-ROC, або крива площі під робочою характеристикою приймача, є графічним зображенням ефективності моделі двійкової класифікації за різних порогових значень класифікації. Він зазвичай використовується в машинному навчанні для оцінки здатності моделі розрізняти два класи, як правило, позитивний клас (наприклад, наявність захворювання) і негативний клас (наприклад, відсутність захворювання).
Давайте спочатку зрозуміємо значення цих двох термінів РПЦ і AUC .
- РПЦ : Робочі характеристики приймача
- AUC : Площа під кривою
Крива робочих характеристик приймача (ROC).
ROC означає робочі характеристики приймача, а крива ROC є графічним зображенням ефективності моделі двійкової класифікації. Він будує графік істинної позитивної частоти (TPR) проти помилкової позитивної частоти (FPR) за різних класифікаційних порогів.
Площа під кривою (AUC) Крива:
AUC означає площу під кривою, а крива AUC представляє площу під кривою ROC. Він вимірює загальну ефективність моделі двійкової класифікації. Оскільки і TPR, і FPR знаходяться в межах від 0 до 1, тож площа завжди буде між 0 і 1, а більше значення AUC означає кращу продуктивність моделі. Наша головна мета — максимізувати цю область, щоб мати найвищий TPR і найнижчий FPR на заданому пороговому значенні. AUC вимірює ймовірність того, що модель призначить випадково вибраному позитивному екземпляру вищу прогнозовану ймовірність порівняно з випадково вибраним негативним екземпляром.
Він представляє ймовірність за допомогою якого наша модель може розрізнити два класи, присутні в нашій цільовій системі.
висота зсуву
Метрика оцінки класифікації ROC-AUC
Ключові терміни, що використовуються в кривих AUC і ROC
1. ТПР і ФПР
Це найпоширеніше визначення, з яким ви могли б зіткнутися, коли б шукали в Google AUC-ROC. По суті, крива ROC — це графік, який показує ефективність моделі класифікації за всіх можливих порогів (поріг — це конкретне значення, за яким ви кажете, що точка належить до певного класу). Крива будується між двома параметрами
- TPR – Справжня позитивна ставка
- FPR – Рівень помилкових позитивних результатів
Перш ніж зрозуміти TPR і FPR, давайте швидко розглянемо матриця плутанини .
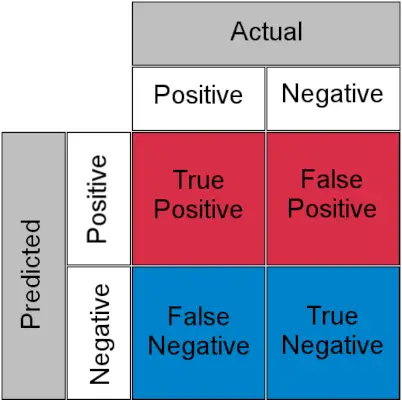
Матриця плутанини для завдання класифікації
- Справжній позитив : Фактичний позитивний і прогнозований як позитивний
- Справжній негатив : фактичне негативне та прогнозоване як негативне
- Помилковий результат (помилка типу I) : Фактично негативно, але прогнозується як позитивно
- Помилково негативний результат (помилка типу II) : Фактично позитивно, але прогнозується як негативно
Простіше кажучи, ви можете назвати помилковий результат a помилкова тривога і хибно-негативний a міс . Тепер давайте подивимося, що таке TPR і FPR.
2. Чутливість / Істинний позитивний показник / Відкликання
По суті, TPR/Recall/Sensitivity — це співвідношення позитивних прикладів, які правильно визначено. Він представляє здатність моделі правильно визначати позитивні випадки та обчислюється таким чином:

Чутливість/запам’ятовування/TPR вимірює частку фактичних позитивних випадків, які модель правильно визначає як позитивні.
3. Хибнопозитивний рівень
FPR – відношення негативних прикладів, які неправильно класифіковані.

4. Конкретність
Специфічність вимірює частку фактичних негативних випадків, які модель правильно визначає як негативні. Він представляє здатність моделі правильно визначати негативні випадки

І, як було сказано раніше, ROC — це не що інше, як графік між TPR і FPR через усі можливі порогові значення, а AUC — це вся площа під цією кривою ROC.
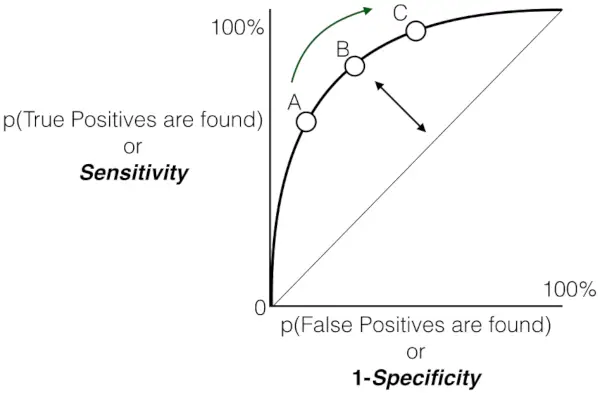
Діаграма чутливості проти хибнопозитивних результатів
Зв'язок між чутливістю, специфічністю, FPR і порогом .
Чутливість і специфічність:
- Зворотне відношення: чутливість і специфічність мають зворотний зв'язок. Коли один збільшується, інший має тенденцію до зменшення. Це відображає властивий компроміс між справді позитивними та справді негативними ставками.
- Налаштування через Threshold: Регулюючи порогове значення, ми можемо контролювати баланс між чутливістю та специфічністю. Нижчі пороги призводять до вищої чутливості (більше справжніх позитивних результатів) за рахунок специфічності (більше хибних позитивних результатів). І навпаки, підвищення порогу підвищує специфічність (менше помилкових позитивних результатів), але приносить в жертву чутливість (більше помилкових негативних результатів).
Порогове значення та частота помилкових позитивних результатів (FPR):
- FPR і зв'язок специфічності: Частота помилкових позитивних результатів (FPR) є просто доповненням до специфічності (FPR = 1 – специфічність). Це означає прямий зв’язок між ними: вища специфічність означає нижчий FPR, і навпаки.
- Зміни FPR з TPR: Подібним чином, як ви помітили, істинний позитивний показник (TPR) і FPR також пов’язані. Збільшення TPR (більше справжніх позитивних результатів) зазвичай призводить до підвищення FPR (більше хибних позитивних результатів). І навпаки, зниження TPR (менша кількість справжніх позитивних результатів) призводить до зниження FPR (менша кількість хибних позитивних результатів)
Як працює AUC-ROC?
Ми розглянули геометричну інтерпретацію, але я вважаю, що її все ще недостатньо для розвитку інтуїції, що стоїть за значенням 0,75 AUC, тепер давайте подивимося на AUC-ROC з імовірнісної точки зору. Давайте спочатку поговоримо про те, чим займається AUC, а пізніше ми побудуємо наше розуміння на основі цього
AUC визначає, наскільки добре модель здатна розрізняти класи.
AUC 0,75 фактично означатиме, що, скажімо, ми беремо дві точки даних, що належать до окремих класів, тоді існує 75% ймовірність, що модель зможе їх відокремити або правильно впорядкувати, тобто позитивна точка має вищу ймовірність прогнозу, ніж негативна. клас. (припущення, що ймовірність прогнозу вища, означає, що точка в ідеалі належатиме до позитивного класу). Ось невеликий приклад, щоб було зрозуміліше.
Індекс | Клас | Ймовірність |
|---|---|---|
P1 | 1 | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Тут ми маємо 6 точок, де P1, P2 і P5 належать до класу 1, а P3, P4 і P6 належать до класу 0, і ми відповідаємо прогнозованим імовірностям у стовпці ймовірності, як ми сказали, якщо взяти дві точки, що належать до окремих класів, то яка ймовірність того, що ранг моделі впорядкує їх правильно.
Ми візьмемо всі можливі пари так, що одна точка належить до класу 1, а інша належить до класу 0, ми матимемо загалом 9 таких пар нижче, це всі 9 можливих пар.
Пара | правильно |
|---|---|
(P1,P3) | Так |
(P1,P4) | Так |
(P1,P6) | Так |
(P2,P3) | Так |
(P2,P4) | Так |
(P2,P6) | Так |
(P3,P5) | Немає |
(P4,P5) | Немає |
(P5,P6) | Так |
Тут стовпець «Правильно» вказує, чи згадана пара правильно впорядкована за рангом на основі передбаченої ймовірності, тобто бал класу 1 має вищу ймовірність, ніж бал класу 0, у 7 із цих 9 можливих пар клас 1 має рейтинг вище, ніж клас 0, або ми можемо сказати, що існує 77% ймовірність того, що якщо ви виберете пару точок, що належать до окремих класів, модель зможе їх правильно розрізнити. Тепер, я думаю, у вас може бути трохи інтуїції за цим числом AUC, просто щоб прояснити будь-які подальші сумніви, давайте перевіримо це за допомогою реалізації Scikit вивчає AUC-ROC.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Вихід:
AUC for our sample data is 0.778>
Коли ми повинні використовувати метрику оцінки AUC-ROC?
У деяких областях використання ROC-AUC може бути не ідеальним. У випадках, коли набір даних дуже незбалансований, крива ROC може дати занадто оптимістичну оцінку продуктивності моделі . Це оптимістичне упередження виникає через те, що коефіцієнт помилкових позитивних результатів (FPR) кривої ROC може стати дуже малим, коли кількість фактичних негативних результатів велика.
Дивлячись на формулу FPR,

ми спостерігаємо ,
- Клас Negative є більшістю, у знаменнику FPR переважають True Negatives, через що FPR стає менш чутливим до змін у прогнозах, пов’язаних з класом меншості (позитивний клас).
- Криві ROC можуть бути доцільними, якщо вартість хибнопозитивних і хибнонегативних результатів збалансована, а набір даних не сильно дисбалансований.
У цьому випадку Криві точного відкликання можна використовувати для забезпечення альтернативної метрики оцінки, яка більше підходить для незбалансованих наборів даних, зосереджуючись на продуктивності класифікатора щодо позитивного (міноритарного) класу.
Припущення про продуктивність моделі
- Висока AUC (близька до 1) вказує на відмінну дискримінаційну здатність. Це означає, що модель ефективна для розрізнення двох класів, а її прогнози надійні.
- Низька AUC (близька до 0) свідчить про низьку ефективність. У цьому випадку моделі важко розрізнити позитивні та негативні класи, і її прогнози можуть бути ненадійними.
- AUC близько 0,5 означає, що модель, по суті, робить випадкові припущення. Він не демонструє здатності розділяти класи, що вказує на те, що модель не вивчає жодних значущих шаблонів із даних.
Розуміння кривої AUC-ROC
На кривій ROC вісь x зазвичай представляє частоту помилкових позитивних результатів (FPR), а вісь y – частоту справжніх позитивних результатів (TPR), також відому як чутливість або запам’ятовування. Таким чином, більш високе значення осі X (праворуч) на кривій ROC вказує на вищий коефіцієнт хибно-позитивних результатів, а вище значення осі Y (у напрямку вгору) вказує на вищий коефіцієнт справді позитивних результатів. Крива ROC є графічним подання компромісу між істинно позитивним показником і хибно позитивним рівнем при різних порогових значеннях. Він показує ефективність моделі класифікації за різних порогів класифікації. AUC (площа під кривою) є підсумковим показником ефективності кривої ROC. Вибір порогового значення залежить від конкретних вимог проблеми, яку ви намагаєтеся вирішити, і компромісу між хибнопозитивними та хибнонегативними результатами. прийнятним у вашому контексті.
- Якщо ви хочете надати пріоритет зменшенню хибних спрацьовувань (зводячи до мінімуму ймовірність позначити щось як позитивне, якщо це не так), ви можете вибрати поріг, який призводить до нижчого рівня хибних спрацьовувань.
- Якщо ви хочете віддати пріоритет збільшенню справжніх позитивних результатів (охоплення якомога більшої кількості фактичних позитивних результатів), ви можете вибрати поріг, який призведе до вищого показника справжніх позитивних результатів.
Розглянемо приклад, щоб проілюструвати, як генеруються криві ROC для різних пороги і як конкретний поріг відповідає матриці плутанини. Припустимо, ми маємо a проблема бінарної класифікації з моделлю, що передбачає, чи є електронний лист спамом (позитивний) чи не спамом (негативний).
Розглянемо гіпотетичні дані,
Справжні мітки: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Прогнозовані ймовірності: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Випадок 1: Порогове значення = 0,5
Справжні мітки | Прогнозовані ймовірності | Прогнозовані мітки |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Матриця плутанини на основі наведених вище прогнозів
| Прогноз = 0 | Прогноз = 1 |
|---|---|---|
Фактичний = 0 | TP=4 | FN=1 |
Фактичний = 1 | FP=0 | TN=5 |
Відповідно,
- Справжній позитивний коефіцієнт (TPR) :
Частка фактичних позитивних результатів, правильно визначених класифікатором, становить

- Частота помилкових позитивних результатів (FPR) :
Частка фактичних негативів, неправильно класифікованих як позитивні



Отже, на порозі 0,5:
- Істинно позитивний коефіцієнт (чутливість): 0,8
- Хибнопозитивний рівень: 0
Тлумачення полягає в тому, що модель за цього порогового значення правильно визначає 80% фактичних позитивних результатів (TPR), але неправильно класифікує 0% фактичних негативних результатів як позитивні (FPR).
Відповідно для різних порогів ми отримаємо,
Випадок 2: Порогове значення = 0,7
Справжні мітки | Прогнозовані ймовірності | Прогнозовані мітки |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 довго нанизувати | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Матриця плутанини на основі наведених вище прогнозів
| Прогноз = 0 | Прогноз = 1 |
|---|---|---|
Фактичний = 0 | TP=5 | FN=0 |
Фактичний = 1 | FP=2 | TN=3 ipconfig для ubuntu |
Відповідно,
- Справжній позитивний коефіцієнт (TPR) :
Частка фактичних позитивних результатів, правильно визначених класифікатором, становить

- Частота помилкових позитивних результатів (FPR) :
Частка фактичних негативів, неправильно класифікованих як позитивні



Випадок 3: Порогове значення = 0,4
Справжні мітки | Прогнозовані ймовірності | Прогнозовані мітки |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Матриця плутанини на основі наведених вище прогнозів
| Прогноз = 0 | Прогноз = 1 |
|---|---|---|
Фактичний = 0 | TP=4 | FN=1 |
Фактичний = 1 | FP=0 | TN=5 |
Відповідно,
- Справжній позитивний показник (TPR) :
Частка фактичних позитивних результатів, правильно визначених класифікатором, становить
- Частота помилкових позитивних результатів (FPR) :
Частка фактичних негативів, неправильно класифікованих як позитивні
Випадок 4: Порогове значення = 0,2
Справжні мітки | Прогнозовані ймовірності | Прогнозовані мітки |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 1 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 1 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Матриця плутанини на основі наведених вище прогнозів
| Прогноз = 0 | Прогноз = 1 |
|---|---|---|
Фактичний = 0 | TP=2 | FN=3 |
Фактичний = 1 | FP=0 | TN=5 |
Відповідно,
- Справжній позитивний коефіцієнт (TPR) :
Частка фактичних позитивних результатів, правильно визначених класифікатором, становить

- Частота помилкових позитивних результатів (FPR) :
Частка фактичних негативів, неправильно класифікованих як позитивні

Випадок 5: Порогове значення = 0,85
Справжні мітки | Прогнозовані ймовірності | Прогнозовані мітки |
|---|---|---|
| 1 | 0,8 | 0 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Матриця плутанини на основі наведених вище прогнозів
| Прогноз = 0 | Прогноз = 1 |
|---|---|---|
Фактичний = 0 | TP=5 | FN=0 |
Фактичний = 1 | FP=4 | TN=1 |
Відповідно,
- Справжній позитивний коефіцієнт (TPR) :
Частка фактичних позитивних результатів, правильно визначених класифікатором, становить
- Частота помилкових позитивних результатів (FPR) :
Частка фактичних негативів, неправильно класифікованих як позитивні


На основі вищенаведеного результату ми побудуємо криву ROC
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Вихід:
З графіка випливає, що:
- Сіра пунктирна лінія представляє найгірший сценарій, де прогнози моделі, тобто TPR є FPR, однакові. Ця діагональна лінія вважається найгіршим сценарієм, що вказує на однакову ймовірність помилкових позитивних і помилкових негативних результатів.
- Оскільки точки відхиляються від випадкової лінії вгадування до верхнього лівого кута, продуктивність моделі покращується.
- Площа під кривою (AUC) є кількісним показником дискримінаційної здатності моделі. Більш високе значення AUC, ближче до 1,0, вказує на чудову продуктивність. Найкраще можливе значення AUC становить 1,0, що відповідає моделі, яка досягає 100% чутливості та 100% специфічності.
Загалом крива робочої характеристики приймача (ROC) служить графічним зображенням компромісу між істинним позитивним показником (чутливістю) і помилковим позитивним показником моделі двійкової класифікації за різних порогів прийняття рішення. Коли крива витончено піднімається до верхнього лівого кута, це означає похвальну здатність моделі розрізняти позитивні та негативні випадки в діапазоні порогів достовірності. Ця висхідна траєкторія вказує на покращену продуктивність із досягненням вищої чутливості при мінімізації помилкових спрацьовувань. Анотовані порогові значення, позначені як A, B, C, D і E, пропонують цінну інформацію про динамічну поведінку моделі на різних рівнях достовірності.
Реалізація з використанням двох різних моделей
Встановлення бібліотек
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
Для того, щоб навчити Випадковий ліс і Логістична регресія моделі та для представлення їхніх кривих ROC з показниками AUC, алгоритм створює дані штучної двійкової класифікації.
Генерування даних і розділення даних
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Використовуючи співвідношення 80-20, алгоритм створює дані штучної двійкової класифікації з 20 ознаками, розділяє їх на набори для навчання та тестування та призначає випадкове початкове число для забезпечення відтворюваності.
Навчання різних моделей
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Використовуючи фіксоване випадкове початкове число для забезпечення повторюваності, метод ініціалізує та навчає модель логістичної регресії на навчальному наборі. Подібним чином він використовує навчальні дані та те саме випадкове початкове число для ініціалізації та навчання моделі випадкового лісу зі 100 деревами.
Прогнози
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Використання тестових даних і навчений Логістична регресія моделі, код передбачає ймовірність позитивного класу. Подібним чином, використовуючи тестові дані, він використовує навчену модель випадкового лісу для створення прогнозованих ймовірностей для позитивного класу.
символ для рядка в java
Створення фрейму даних
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Використовуючи тестові дані, код створює DataFrame під назвою test_df зі стовпцями з позначками True, Logistic і RandomForest, додаючи справжні мітки та прогнозовані ймовірності з моделей Random Forest і Logistic Regression.
Побудуйте криву ROC для моделей
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Вихід:

Код генерує графік із фігурами розміром 8 на 6 дюймів. Він обчислює криву AUC і ROC для кожної моделі (випадковий ліс і логістична регресія), а потім будує криву ROC. The ROC крива для випадкового вгадування також представлено червоною пунктирною лінією, а для візуалізації встановлюються мітки, заголовок і легенда.
Як використовувати ROC-AUC для багатокласової моделі?
Для налаштування кількох класів ми можемо просто використати методологію «один проти всіх», і ви матимете одну криву ROC для кожного класу. Скажімо, у вас є чотири класи A, B, C і D, тоді будуть криві ROC і відповідні значення AUC для всіх чотирьох класів, тобто один раз A буде одним класом, а B, C і D разом будуть іншими класами. подібним чином B є одним класом, а A, C і D об’єднані як інші класи тощо.
Загальні кроки для використання AUC-ROC у контексті багатокласової моделі класифікації:
Методологія «Один проти всіх»:
- Для кожного класу у вашій багатокласовій задачі розглядайте його як позитивний клас, об’єднуючи всі інші класи в негативний клас.
- Навчіть двійковий класифікатор для кожного класу з рештою класів.
Обчисліть AUC-ROC для кожного класу:
- Тут ми будуємо криву ROC для даного класу проти решти.
- Побудуйте криві ROC для кожного класу на одному графіку. Кожна крива представляє ефективність розрізнення моделі для певного класу.
- Вивчіть оцінки AUC для кожного класу. Вищий показник AUC вказує на кращу дискримінацію для цього конкретного класу.
Реалізація AUC-ROC у багатокласовій класифікації
Імпорт бібліотек
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Програма створює штучні багатокласові дані, розділяє їх на навчальні та тестові набори, а потім використовує One-vs-Restclassifier техніка для навчання класифікаторів як для випадкового лісу, так і для логістичної регресії. Нарешті, він малює багатокласові криві ROC двох моделей, щоб продемонструвати, наскільки добре вони розрізняють різні класи.
Генерування даних і розбиття
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Три класи та двадцять ознак складають синтетичні мультикласові дані, створені кодом. Після бінаризації міток дані поділяються на набори для навчання та тестування у співвідношенні 80-20.
Навчальні моделі
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Програма навчає дві багатокласові моделі: модель випадкового лісу зі 100 оцінювачами та модель логістичної регресії з Підхід «один проти решти». . За допомогою навчального набору даних обидві моделі підігнані.
Побудова кривої AUC-ROC
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Вихід:

Криві ROC моделей випадкового лісу та логістичної регресії та показники AUC обчислюються за кодом для кожного класу. Потім будуються багатокласові криві ROC, що показують ефективність розрізнення кожного класу та містять лінію, яка представляє випадкове вгадування. Отриманий графік пропонує графічну оцінку ефективності класифікації моделей.
Висновок
У машинному навчанні продуктивність моделей двійкової класифікації оцінюється за допомогою важливого показника під назвою «Площа під робочою характеристикою приймача» (AUC-ROC). За різними пороговими значеннями для прийняття рішень він показує, як взаємодіють чутливість і специфічність. Більше розрізнення між позитивними та негативними випадками зазвичай демонструє модель з вищим показником AUC. У той час як 0,5 означає шанс, 1 означає бездоганне виконання. Оптимізації та вибору моделі допомагає корисна інформація, яку пропонує крива AUC-ROC про здатність моделі розрізняти класи. Під час роботи з незбалансованими наборами даних або додатками, де помилкові спрацьовування та помилкові негативи мають різну вартість, це особливо корисно як комплексний захід.
Поширені запитання щодо кривої AUC ROC у машинному навчанні
1. Що таке крива AUC-ROC?
Для різних класифікаційних порогів компроміс між істинно позитивною частотою (чутливість) і помилково позитивною частотою (специфічність) графічно представлений кривою AUC-ROC.
2. Як виглядає ідеальна крива AUC-ROC?
Площа 1 на ідеальній кривій AUC-ROC означатиме, що модель досягає оптимальної чутливості та специфічності за всіма пороговими значеннями.
3. Що означає значення AUC 0,5?
AUC 0,5 вказує на те, що продуктивність моделі порівнянна з продуктивністю випадкової випадковості. Це говорить про відсутність здатності розрізняти.
4. Чи можна використовувати AUC-ROC для багатокласової класифікації?
AUC-ROC часто застосовується до питань, що стосуються двійкової класифікації. Варіації, такі як макро-середнє або мікро-середнє AUC, можуть бути прийняті до уваги для багатокласової класифікації.
5. Як крива AUC-ROC корисна для оцінки моделі?
Здатність моделі розрізняти класи всебічно підсумовується кривою AUC-ROC. Це особливо корисно при роботі з незбалансованими наборами даних.