Доглядач зоопарку це розподілена служба координації з відкритим кодом для розподілених програм. Він надає простий набір примітивів для реалізації служб вищого рівня для синхронізації, підтримки конфігурації, групування та іменування.
У розподіленій системі є кілька вузлів або машин, які повинні спілкуватися один з одним і координувати свої дії. ZooKeeper забезпечує спосіб переконатися, що ці вузли знають один про одного та можуть координувати свої дії. Це робиться шляхом підтримки ієрархічного дерева вузлів даних, які називаються Зноди , який можна використовувати для зберігання та отримання даних і підтримки інформації про стан. ZooKeeper надає набір примітивів, таких як блокування, бар’єри та черги, які можна використовувати для координації дій вузлів у розподіленій системі. Він також надає такі функції, як вибір лідера, перехід після відмови та відновлення, які можуть допомогти забезпечити стійкість системи до збоїв. ZooKeeper широко використовується в розподілених системах, таких як Hadoop, Kafka і HBase, і він став важливим компонентом багатьох розподілених програм.
Навіщо нам це потрібно?
- Координаційні послуги : Інтеграція/комунікація послуг у розподіленому середовищі.
- Послуги координації складно отримати правильно. Вони особливо схильні до таких помилок, як умови перегонів і взаємоблокування.
- Стан гонки - Дві або більше систем намагаються виконати певне завдання.
- Тупикові ситуації – Дві або більше операцій чекають одна одну.
- Щоб полегшити координацію між розподіленими середовищами, розробники придумали ідею під назвою zookeeper, щоб їм не доводилося звільняти розподілені програми від відповідальності за впровадження координаційних служб з нуля.
Що таке розподілена система?
- Кілька комп’ютерних систем працюють над однією проблемою.
- Це мережа, яка складається з автономних комп’ютерів, з’єднаних за допомогою розподіленого проміжного програмного забезпечення.
- Ключові особливості : Одночасний, спільний доступ до ресурсів, незалежний, глобальний, більша відмовостійкість і співвідношення ціна/продуктивність набагато краще.
- Ключова мета s: прозорість, надійність, продуктивність, масштабованість.
- Виклики : безпека, помилки, координація та спільне використання ресурсів.
Виклик координації
- Чому координація в розподіленій системі є важкою проблемою?
- Координація або управління конфігурацією для розподіленої програми, яка має багато систем.
- Головний вузол, де зберігаються дані кластера.
- Робочі вузли або підлеглі вузли отримують дані від цього головного вузла.
- єдина точка відмови.
- синхронізація не проста.
- Потрібні ретельний дизайн і впровадження.
Apache Zookeeper
Apache Zookeeper — це розподілена служба координації з відкритим кодом для розподілених систем. Він забезпечує центральне місце для розподілених програм для зберігання даних, спілкування один з одним і координації діяльності. Zookeeper використовується в розподілених системах для координації розподілених процесів і послуг. Він забезпечує просту деревоподібну модель даних, простий API і розподілений протокол для забезпечення узгодженості та доступності даних. Zookeeper розроблений як високонадійний і відмовостійкий, і він може працювати з високими рівнями читання та запису.
Zookeeper реалізований на Java і широко використовується в розподілених системах, зокрема в екосистемі Hadoop. Це проект Apache Software Foundation і випущений за ліцензією Apache 2.0.
Архітектура Zookeeper
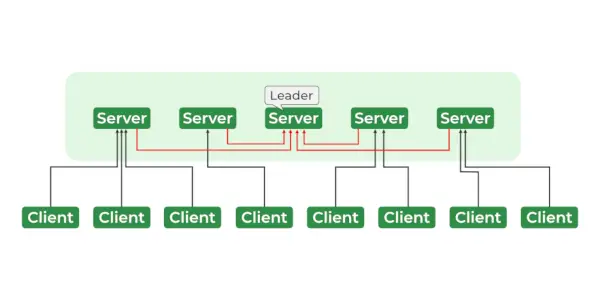
Послуги доглядача зоопарку
Архітектура ZooKeeper складається з ієрархії вузлів, званих znodes, організованих у деревоподібну структуру. Кожен znode може зберігати дані та має набір дозволів, які контролюють доступ до znode. Зноди організовані в ієрархічному просторі імен, подібному до файлової системи. У корені ієрархії знаходиться кореневий znode, а всі інші znode є нащадками кореневого znode. Ієрархія схожа на ієрархію файлової системи, де кожен znode може мати дітей, онуків і так далі.
Важливі компоненти Zookeeper
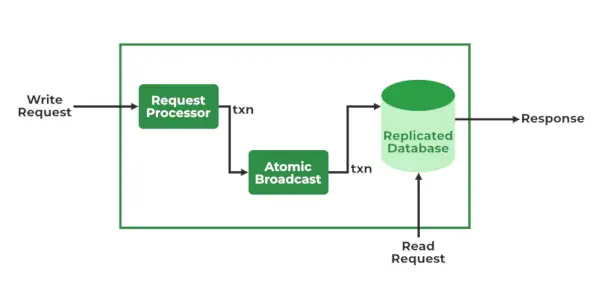
Послуги ZooKeeper
- Лідер і послідовник
- Процесор запитів – Активний у Leader Node і відповідає за обробку запитів на запис. Після обробки він надсилає зміни до наступних вузлів
- Атомне мовлення – Присутній як у ведучому вузлі, так і в наступному вузлі. Він відповідає за надсилання змін до інших вузлів.
- Бази даних в пам'яті (Репліковані бази даних) – відповідає за зберігання даних у зоопарку. Кожен вузол містить свої власні бази даних. Дані також записуються у файлову систему, що забезпечує можливість відновлення у разі будь-яких проблем із кластером.
Інші компоненти
- Клієнт – Один із вузлів нашого розподіленого кластера додатків. Доступ до інформації з сервера. Кожен клієнт надсилає повідомлення на сервер, щоб повідомити серверу, що клієнт живий.
- Сервер – Надає всі послуги клієнту. Висловлює подяку клієнту.
- Ансамбль – Група серверів Zookeeper. Мінімальна кількість вузлів, необхідних для формування ансамблю, становить 3.
Модель даних Zookeeper
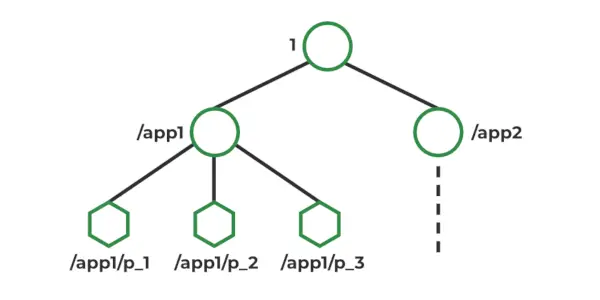
Модель даних ZooKeeper
У Zookeeper дані зберігаються в ієрархічному просторі імен, подібному до файлової системи. Кожен вузол у просторі імен називається Znode, і він може зберігати дані та мати дітей. Znodes подібні до файлів і каталогів у файловій системі. Zookeeper надає простий API для створення, читання, запису та видалення Znodes. Він також надає механізми для виявлення змін даних, що зберігаються в Znodes, таких як годинник і тригери. Znodes підтримує структуру статистики, яка включає: номер версії, ACL, позначку часу, довжину даних
Типи Знодів :
- Наполегливість : Живі, доки їх явно не буде видалено.
- Ефемерний : активний, доки клієнтське підключення не активне.
- Послідовний : або постійний, або ефемерний.
Навіщо нам ZooKeeper у Hadoop?
Zookeeper використовується для керування та координації вузлів у кластері Hadoop, включаючи NameNode, DataNode і ResourceManager. У кластері Hadoop Zookeeper допомагає:
- Зберігати конфігураційну інформацію: Zookeeper зберігає конфігураційну інформацію для кластера Hadoop, включаючи розташування NameNode, DataNode і ResourceManager.
- Керуйте станом кластера: Zookeeper відстежує стан вузлів у кластері Hadoop і може використовуватися для виявлення, коли вузол вийшов з ладу або став недоступним.
- Координуйте розподілені процеси: Zookeeper можна використовувати для координації розподілених процесів, таких як планування завдань і розподіл ресурсів, між вузлами в кластері Hadoop.
Zookeeper допомагає забезпечити доступність і надійність кластера Hadoop, надаючи центральну службу координації для вузлів у кластері.
Як працює ZooKeeper у Hadoop?
ZooKeeper працює як розподілена файлова система та надає простий набір API, які дозволяють клієнтам читати та записувати дані у файлову систему. Він зберігає свої дані в деревоподібній структурі під назвою znode, яку можна розглядати як файл або каталог у традиційній файловій системі. ZooKeeper використовує алгоритм консенсусу, щоб гарантувати, що всі його сервери мають послідовне уявлення про дані, що зберігаються в Znodes. Це означає, що якщо клієнт записує дані в znode, ці дані будуть відтворені на всі інші сервери в ансамблі ZooKeeper.
Однією з важливих особливостей ZooKeeper є його здатність підтримувати поняття годинника. Годинник дозволяє клієнту реєструватися для сповіщень, коли дані, що зберігаються в znode, змінюються. Це може бути корисним для моніторингу змін даних, що зберігаються в ZooKeeper, і реагування на ці зміни в розподіленій системі.
У Hadoop ZooKeeper використовується для різних цілей, зокрема:
- Зберігання конфігураційної інформації: ZooKeeper використовується для зберігання конфігураційної інформації, яка використовується кількома компонентами Hadoop. Наприклад, він може використовуватися для зберігання розташування NameNodes у кластері Hadoop або адрес вузлів JobTracker.
- Забезпечення розподіленої синхронізації: ZooKeeper використовується для координації діяльності різних компонентів Hadoop і забезпечення їх узгодженої спільної роботи. Наприклад, його можна використовувати, щоб переконатися, що в кластері Hadoop одночасно активний лише один NameNode.
- Підтримка імен: ZooKeeper використовується для підтримки централізованої служби імен для компонентів Hadoop. Це може бути корисним для ідентифікації та розміщення ресурсів у розподіленій системі.
ZooKeeper є важливим компонентом Hadoop і відіграє вирішальну роль у координації діяльності його різних підкомпонентів.
Читання та запис у Apache Zookeeper
ZooKeeper надає простий і надійний інтерфейс для читання та запису даних. Дані зберігаються в ієрархічному просторі імен, подібному до файлової системи, з вузлами, які називаються znodes. Кожен знод може зберігати дані та мати дочірні зноди. Клієнти ZooKeeper можуть читати та записувати дані в ці вузли за допомогою методів getData() і setData() відповідно. Ось приклад читання та запису даних за допомогою ZooKeeper Java API:
Java
// Connect to the ZooKeeper ensemble> ZooKeeper zk =>new> ZooKeeper(>'localhost:2181'>,>3000>,>null>);> // Write data to the znode '/myZnode'> String path =>'/myZnode'>;> String data =>'hello world'>;> zk.create(path, data.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);> // Read data from the znode '/myZnode'> byte>[] bytes = zk.getData(path,>false>,>null>);> String readData =>new> String(bytes);> // Prints 'hello world'> System.out.println(readData);> // Closing the connection> // to the ZooKeeper ensemble> zk.close();> |
>
>
Python3
from> kazoo.client>import> KazooClient> # Connect to ZooKeeper> zk>=> KazooClient(hosts>=>'localhost:2181'>)> zk.start()> # Create a node with some data> zk.ensure_path(>'/gfg_node'>)> zk.>set>(>'/gfg_node'>, b>'some_data'>)> # Read the data from the node> data, stat>=> zk.get(>'/gfg_node'>)> print>(data)> # Stop the connection to ZooKeeper> zk.stop()> |
>
k алгоритм кластеризації
>
Сесія та годинники
Сесія
- Запити в сеансі виконуються в порядку FIFO.
- Щойно сеанс буде встановлено, ідентифікатор сесії закріплюється за клієнтом.
- Клієнт надсилає серцебиття щоб сесія залишалася дійсною
- Тайм-аут сеансу зазвичай представлений у мілісекундах
Годинники
- Годинники — це механізми, за допомогою яких клієнти отримують повідомлення про зміни в Zookeeper
- Клієнт може дивитися під час читання конкретного znode.
- Зміни znodes — це модифікації даних, пов’язаних із znode, або зміни в дочірніх нодах znode.
- Годинники спрацьовують лише один раз.
- Якщо сесія закінчилася, спостереження також видаляються.