Ми читаємо лінійні структури даних, такі як масив, зв’язаний список, стек і черга, у яких усі елементи розташовані послідовним чином. Для різних типів даних використовуються різні структури даних.
Для вибору структури даних враховуються деякі фактори:
Дерево також є однією зі структур даних, що представляють ієрархічні дані. Припустімо, що ми хочемо показати співробітників і їхні посади в ієрархічній формі, тоді її можна представити, як показано нижче:
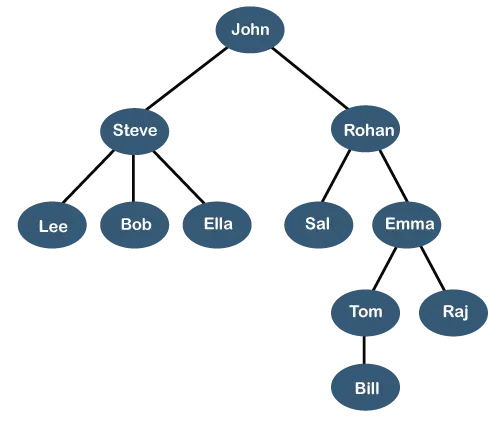
Дерево вище показує ієрархія організації якоїсь компанії. У наведеній вище структурі Джон є генеральний директор компанії, і Джон має двох прямих підлеглих, названих як Стів і Рохан . Стів має трьох прямих підлеглих Лі, Боб, Елла де Стів є менеджером. Боб має двох прямих підлеглих повинен і Емма . Емма має двох прямих підпорядкованих ім Том і Радж . У Тома є один прямий підпорядкований Білл . Ця конкретна логічна структура відома як a дерево . Його будова схоже на справжнє дерево, тому його назвали a дерево . У цій структурі корінь знаходиться вгорі, а її гілки рухаються вниз. Тому можна сказати, що структура даних Tree є ефективним способом зберігання даних в ієрархічній формі.
Давайте розберемося з деякими ключовими моментами структури даних дерева.
рядок внутр
- Деревоподібна структура даних визначається як набір об’єктів або сутностей, відомих як вузли, які пов’язані між собою для представлення або імітації ієрархії.
- Деревоподібна структура даних є нелінійною структурою даних, оскільки вона не зберігається послідовно. Це ієрархічна структура, оскільки елементи в дереві розташовані на кількох рівнях.
- У структурі даних дерева верхній вузол називається кореневим вузлом. Кожен вузол містить деякі дані, і дані можуть бути будь-якого типу. У наведеній вище структурі дерева вузол містить ім’я співробітника, тому типом даних буде рядок.
- Кожен вузол містить деякі дані та посилання або посилання на інші вузли, які можна назвати дочірніми.
Деякі основні терміни, що використовуються в структурі даних дерева.
Розглянемо структуру дерева, яка показана нижче:

У наведеній вище структурі кожен вузол позначено деяким номером. Кожна стрілка, показана на малюнку вище, відома як a посилання між двома вузлами.
Властивості структури даних Tree

На основі властивостей структури даних дерева дерева класифікуються за різними категоріями.
Реалізація дерева
Структуру даних дерева можна створити шляхом динамічного створення вузлів за допомогою покажчиків. Дерево в пам'яті можна представити, як показано нижче:

Наведений вище малюнок показує представлення структури даних дерева в пам'яті. У наведеній вище структурі вузол містить три поля. Друге поле зберігає дані; перше поле зберігає адресу лівого дочірнього елемента, а третє поле зберігає адресу правого дочірнього елемента.
У програмуванні структуру вузла можна визначити як:
struct node { int data; struct node *left; struct node *right; } Наведену вище структуру можна визначити лише для бінарних дерев, оскільки двійкове дерево може мати щонайбільше двох дітей, а загальні дерева можуть мати більше двох дітей. Структура вузла для загальних дерев буде іншою порівняно з бінарним деревом.
Аплікації з дерев
Ось приклади застосування дерев:
python друкує до 2 знаків після коми
Типи структури даних дерева
Нижче наведено типи деревовидної структури даних:

Може бути п кількість піддерев у загальному дереві. У загальному дереві піддерева не впорядковані, оскільки вузли піддерева не можна впорядкувати.
Кожне непорожнє дерево має низхідне ребро, і ці ребра з’єднані з вузлами, відомими як дочірні вузли . Кореневий вузол позначено рівнем 0. Вузли, які мають одного батька, називаються брати і сестри .

Щоб дізнатися більше про бінарне дерево, натисніть посилання нижче:
https://www.javatpoint.com/binary-tree
Кожен вузол у лівому піддереві має містити значення, менше значення кореневого вузла, а значення кожного вузла правого піддерева має бути більшим за значення кореневого вузла.
Вузол можна створити за допомогою визначеного користувачем типу даних, відомого як структура, як показано нижче:
struct node { int data; struct node *left; struct node *right; } Вище наведено структуру вузла з трьома полями: поле даних, друге поле — лівий покажчик типу вузла, а третє поле — правий покажчик типу вузла.
Щоб дізнатися більше про бінарне дерево пошуку, натисніть посилання нижче:
https://www.javatpoint.com/binary-search-tree
Це один із типів бінарного дерева, або можна сказати, що це варіант бінарного дерева пошуку. Дерево AVL задовольняє властивість бінарне дерево а також з двійкове дерево пошуку . Це самобалансуюче бінарне дерево пошуку, винайдене Адельсон Вельскі Ліндас . Тут самобалансування означає балансування висот лівого піддерева та правого піддерева. Це балансування вимірюється в термінах балансуючий фактор .
Ми можемо розглядати дерево як дерево AVL, якщо дерево підкоряється бінарному дереву пошуку, а також фактору балансу. Коефіцієнт балансування можна визначити як різниця між висотою лівого піддерева і висотою правого піддерева . Значення балансуючого коефіцієнта має бути 0, -1 або 1; отже, кожен вузол у дереві AVL повинен мати значення коефіцієнта балансування 0, -1 або 1.
Щоб дізнатися більше про дерево AVL, натисніть посилання нижче:
https://www.javatpoint.com/avl-tree
Червоно-чорне дерево це бінарне дерево пошуку. Обов’язкова умова червоно-чорного дерева полягає в тому, що ми повинні знати про бінарне дерево пошуку. У бінарному дереві пошуку значення лівого піддерева має бути меншим за значення цього вузла, а значення правого піддерева має бути більшим за значення цього вузла. Як відомо, часова складність бінарного пошуку в середньому становить log2n, найкращий випадок – O(1), а найгірший – O(n).
обробка винятків у java
Коли над деревом виконується будь-яка операція, ми хочемо, щоб наше дерево було збалансованим, щоб усі операції, такі як пошук, вставка, видалення тощо, займали менше часу, і всі ці операції мали часову складність журнал2п.
Червоно-чорне дерево це самобалансуюче бінарне дерево пошуку. Дерево AVL також є бінарним деревом пошуку з балансуванням висоти чому нам потрібне червоно-чорне дерево . У дереві AVL ми не знаємо, скільки обертів знадобиться для збалансування дерева, але в червоно-чорному дереві для збалансування дерева потрібно максимум 2 оберти. Він містить один додатковий біт, який представляє або червоний, або чорний колір вузла, щоб забезпечити балансування дерева.
Структура даних дерева розсувних даних також є бінарним деревом пошуку, у якому нещодавно доступний елемент розміщується в кореневій позиції дерева шляхом виконання деяких операцій обертання. тут, розкидаючись означає нещодавно доступний вузол. Це самобалансування двійкове дерево пошуку без явної умови балансу, наприклад AVL дерево.
Можливо, висота дерева зсуву не збалансована, тобто висота лівого та правого піддерев може відрізнятися, але операції в дереві зсуву виконуються в порядку спокійний час де п – кількість вузлів.
Дерево Splay є збалансованим деревом, але його не можна вважати деревом із збалансованою висотою, оскільки після кожної операції виконується обертання, що призводить до збалансованого дерева.
Структура даних Treap походить від структури даних Tree і Heap. Таким чином, він включає в себе властивості обох структур даних Tree і Heap. У бінарному дереві пошуку кожен вузол лівого піддерева має бути рівним або меншим за значення кореневого вузла, а кожен вузол правого піддерева має бути рівним або більшим за значення кореневого вузла. У структурі даних купи і праве, і ліве піддерева містять більші ключі, ніж кореневі; отже, можна сказати, що кореневий вузол містить найменше значення.
У структурі даних treap кожен вузол має обидва ключ і пріоритет де ключ виводиться з бінарного дерева пошуку, а пріоритет – зі структури даних купи.
The Треап Структура даних має дві властивості, наведені нижче:
- Правий дочірній елемент вузла>= поточний вузол і лівий дочірній елемент вузла<=current node (binary tree)< li>
- Діти будь-якого піддерева мають бути більшими за вузол (купу)
В-дерево є збалансованим м-шлях дерево де м визначає порядок дерева. Досі ми читали, що вузол містить лише один ключ, але b-дерево може мати більше одного ключа та більше 2 дочірніх елементів. Він завжди підтримує відсортовані дані. У бінарному дереві можливо, що листові вузли можуть бути на різних рівнях, але в b-дереві всі листові вузли мають бути на одному рівні.
Якщо порядок m, то вузол має такі властивості:
- Кожен вузол b-дерева може мати максимум м дітей
- Для мінімальних дочірніх вузлів листовий вузол має 0 дочірніх елементів, кореневий вузол має мінімум 2 дочірніх вузла, а внутрішній вузол має мінімальну межу m/2 дочірніх елементів. Наприклад, значення m дорівнює 5, що означає, що вузол може мати 5 дітей, а внутрішні вузли можуть містити максимум 3 дітей.
- Кожен вузол має максимум (m-1) ключів.
Кореневий вузол має містити принаймні 1 ключ, а всі інші вузли мають містити щонайменше стеля м/2 мінус 1 ключі.