Таблиці Excel дуже інтуїтивні та зручні для користувача, що робить їх ідеальними для роботи з великими наборами даних навіть для менш технічних людей. Якщо ви шукаєте місця, де можна навчитися маніпулювати та автоматизувати матеріали у файлах Excel за допомогою Python , не шукайте далі. Ви в потрібному місці.
У цій статті ви дізнаєтеся, як використовувати панди для роботи з електронними таблицями Excel. У цій статті ми дізнаємося про:
- Прочитайте Файл Excel за допомогою Pandas у Python
- Встановлення та імпорт Pandas
- Читання кількох аркушів Excel за допомогою Pandas
- Застосування різних функцій Pandas
Читання файлу Excel за допомогою Pandas у Python
Встановлення Pandas
Щоб встановити Pandas у Python, ми можемо використати таку команду в командному рядку:
pip install pandas>
Щоб встановити Pandas в Anaconda, ми можемо використати таку команду в Anaconda Terminal:
conda install pandas>
Імпорт Pandas
Перш за все, нам потрібно імпортувати модуль Pandas, що можна зробити за допомогою команди:
Python3
import> pandas as pd> |
>
>
Вхідний файл: Припустімо, що файл Excel виглядає так
Аркуш 1:

Аркуш 1
Аркуш 2:
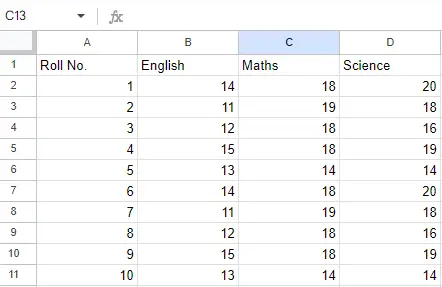
Аркуш 2
Тепер ми можемо імпортувати файл Excel за допомогою функції read_excel у Pandas, щоб прочитати файл Excel за допомогою Pandas у Python. Другий оператор читає дані з Excel і зберігає їх у фреймі даних pandas, який представлено змінною newData.
Python3
перетворення int на рядок у java
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Вихід:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Завантаження кількох аркушів за допомогою методу Concat().
Якщо в книзі Excel кілька аркушів, команда імпортує дані з першого аркуша. Щоб створити фрейм даних із усіма аркушами в робочій книзі, найпростішим способом є створення різних фреймів даних окремо, а потім об’єднати їх. Метод read_excel приймає аргумент sheet_name і index_col, де ми можемо вказати аркуш, з якого має бути створена рамка, а index_col визначає стовпець заголовка, як показано нижче:
приклад:
Третій оператор об'єднує обидва аркуші. Тепер, щоб перевірити весь кадр даних, ми можемо просто виконати таку команду:
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Вихід:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Методи Head() і Tail() у Panda
Щоб переглянути 5 стовпців зверху та знизу кадру даних, ми можемо виконати команду. Це голова() і хвіст() Метод також приймає аргументи як числа для кількості стовпців для показу.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Вихід:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Метод Shape().
The метод shape(). можна використовувати для перегляду кількості рядків і стовпців у кадрі даних наступним чином:
Python3
newData.shape> |
>
>
Вихід:
(20, 3)>
Метод Sort_values() у Pandas
Якщо будь-який стовпець містить числові дані, ми можемо відсортувати цей стовпець за допомогою sort_values() метод у pandas наступним чином:
Python3
char до рядка в java
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Тепер припустімо, що нам потрібні 5 верхніх значень відсортованого стовпця, тут ми можемо використати метод head():
Python3
sorted_column.head(>5>)> |
>
>
Вихід:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Ми можемо зробити це з будь-яким числовим стовпцем кадру даних, як показано нижче:
Python3
замінити рядок у рядку java
newData[>'Maths'>].head()> |
>
>
Вихід:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Метод Pandas Describe().
А тепер припустімо, що наші дані здебільшого чисельні. Ми можемо отримати статистичну інформацію, як-от середнє, максимальне, мінімальне значення тощо про кадр даних, використовуючи описати() метод, як показано нижче:
Python3
newData.describe()> |
>
>
Вихід:
як перейменувати каталог в linux
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Це також можна зробити окремо для всіх числових стовпців за допомогою такої команди:
Python3
newData[>'English'>].mean()> |
>
>
Вихід:
14.3>
Іншу статистичну інформацію також можна розрахувати за допомогою відповідних методів. Як і в Excel, формули також можна застосовувати, а обчислювані стовпці можна створювати таким чином:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
Вихід:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Після обробки даних у кадрі даних ми можемо експортувати дані назад у файл Excel за допомогою методу to_excel. Для цього нам потрібно вказати вихідний файл Excel, куди мають бути записані перетворені дані, як показано нижче:
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Вихід:
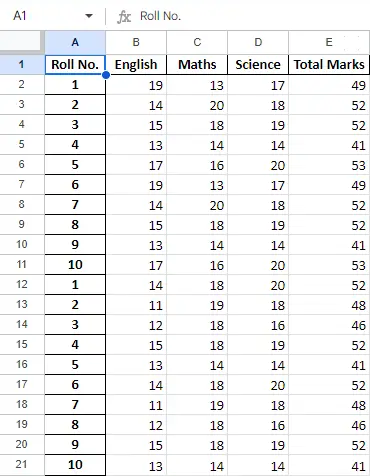
Остаточний лист