Ключове слово IDENTITY є властивістю SQL Server. Якщо для стовпця таблиці визначено властивість ідентичності, його значення буде автоматично згенерованим інкрементним значенням . Це значення створюється сервером автоматично. Тому ми не можемо вручну ввести значення в стовпець ідентичності як користувач. Отже, якщо ми позначимо стовпець як ідентичність, SQL Server заповнить його в автоматичному порядку.
Синтаксис
Нижче наведено синтаксис для ілюстрації використання властивості IDENTITY у SQL Server:
IDENTITY[(seed, increment)]
Наведені вище параметри синтаксису пояснюються нижче:
Давайте зрозуміємо цю концепцію на простому прикладі.
Припустимо, ми маємо ' студент ' стіл, і ми хочемо ID студента генеруватись автоматично. Ми маємо початок студентського квитка 10 і хочете збільшити його на 1 з кожним новим ідентифікатором. У цьому сценарії необхідно визначити такі значення.
насіння: 10
Приріст: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
ПРИМІТКА. Для таблиці в SQL Server дозволено лише один ідентифікаційний стовпець.
Приклад IDENTITY SQL Server
Давайте розберемося, як ми можемо використовувати властивість ідентичності в таблиці. Властивість ідентичності в стовпці можна встановити під час створення нової таблиці або після її створення. Тут ми розглянемо обидва випадки на прикладах.
Властивість IDENTITY з новою таблицею
Наступний оператор створить нову таблицю з властивістю identity у вказаній базі даних:
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Далі ми вставимо новий рядок у цю таблицю за допомогою ВИХІД пункт, щоб побачити автоматично згенерований ідентифікатор особи:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
Виконання цього запиту призведе до наступного результату:
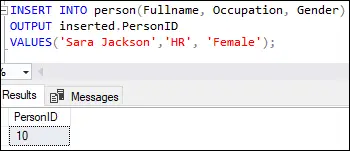
Цей вихід показує, що перший рядок було вставлено зі значенням десять у PersonID стовпець, як зазначено в стовпці ідентичності визначення таблиці.
Давайте вставимо ще один рядок у стіл осіб як зазначено нижче:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
Цей запит поверне такі результати:

Цей результат показує, що другий рядок було вставлено зі значенням 11, а третій рядок зі значенням 12 у стовпці PersonID.
Властивість IDENTITY з наявною таблицею
Ми пояснимо цю концепцію, спочатку видаливши наведену вище таблицю та створивши їх без властивості ідентифікації. Виконайте наведений нижче оператор, щоб видалити таблицю:
DROP TABLE person;
Далі ми створимо таблицю за допомогою наведеного нижче запиту:
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Якщо ми хочемо додати новий стовпець із властивістю identity в існуючу таблицю, нам потрібно використати команду ALTER. Наведений нижче запит додасть PersonID як стовпець ідентичності в таблиці person:
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
Додавання значення в стовпець ідентичності явно
Якщо ми додамо новий рядок у наведену вище таблицю, явно вказавши значення стовпця ідентичності, SQL Server видасть помилку. Перегляньте запит нижче:
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
Виконання цього запиту призведе до такої помилки:

Щоб явно вставити значення стовпця ідентичності, нам потрібно спочатку встановити значення IDENTITY_INSERT у положення ON. Далі виконайте операцію вставки, щоб додати новий рядок до таблиці, а потім встановіть значення IDENTITY_INSERT OFF. Перегляньте наведений нижче сценарій коду:
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT ON дозволяє користувачам розміщувати дані в стовпцях ідентичності, в той час як IDENTITY_INSERT ВИМКНЕНО не дозволяє їм додавати значення до цього стовпця.
Виконання сценарію коду відобразить наведені нижче результати, де ми бачимо, що ідентифікатор особи зі значенням 14 успішно вставлено.

Функція IDENTITY
SQL Server надає деякі функції ідентифікації для роботи зі стовпцями IDENTITY у таблиці. Ці функції ідентифікації перераховані нижче:
- Функція @@IDENTITY
- Функція SCOPE_IDENTITY().
- Функція IDENT_CURRENT
- Функція IDENTITY
Давайте розглянемо функції IDENTITY на кількох прикладах.
Функція @@IDENTITY
@@IDENTITY – це визначена системою функція, яка відображає останнє значення ідентифікатора (максимальне використане значення ідентичності), створене в таблиці для стовпця IDENTITY у тому самому сеансі. Цей стовпець функції повертає значення ідентичності, згенероване оператором після вставлення нового запису в таблицю. Він повертає a НУЛЬ значення, коли ми виконуємо запит, який не створює значень IDENTITY. Він завжди працює в рамках поточного сеансу. Його не можна використовувати віддалено.
приклад
Припустімо, що поточне максимальне значення ідентифікатора в таблиці person дорівнює 13. Тепер ми додамо один запис у той самий сеанс, який збільшує значення ідентифікатора на одиницю. Потім ми скористаємося функцією @@IDENTITY, щоб отримати останнє значення ідентичності, створене в тому самому сеансі.
Ось повний сценарій коду:
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
Виконання сценарію поверне наступний результат, де ми бачимо, що максимальне використане значення ідентичності становить 14.

Функція SCOPE_IDENTITY().
SCOPE_IDENTITY() – це визначена системою функція для відобразити останнє значення ідентифікатора у таблиці в поточній області. Ця область може бути модулем, тригером, функцією або збереженою процедурою. Вона схожа на функцію @@IDENTITY(), за винятком того, що ця функція має лише обмежену область. Функція SCOPE_IDENTITY повертає NULL, якщо ми виконуємо її перед операцією вставки, яка генерує значення в тій самій області.
приклад
Наведений нижче код використовує функції @@IDENTITY і SCOPE_IDENTITY() в одному сеансі. У цьому прикладі спочатку буде показано останнє значення ідентичності, а потім буде вставлено один рядок у таблицю. Далі він виконує обидві функції ідентифікації.
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
Виконання коду відобразить те саме значення в поточному сеансі та аналогічний обсяг. Перегляньте вихідне зображення нижче:

Тепер ми побачимо, чим обидві функції відрізняються на прикладі. Спочатку ми створимо дві таблиці з іменами дані_працівника і відділ використовуючи наведений нижче оператор:
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
Далі ми створюємо тригер INSERT у таблиці employee_data. Цей тригер викликається, щоб вставити рядок у таблицю відділу кожного разу, коли ми вставляємо рядок у таблицю employee_data.
Наведений нижче запит створює тригер для вставки значення за умовчанням 'ВОНО' у таблиці відділу для кожного запиту вставки в таблицю employee_data:
шлях, встановлений у java
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
Після створення тригера ми збираємося вставити один запис у таблицю Emploee_data та побачити результати обох функцій @@IDENTITY та SCOPE_IDENTITY().
INSERT INTO employee_data VALUES ('John Mathew');
Виконання запиту додасть один рядок у таблицю employee_data та згенерує значення ідентифікатора в тому самому сеансі. Коли запит на вставку виконується в таблиці employee_data, він автоматично викликає тригер для додавання одного рядка в таблицю відділу. Початкове значення ідентифікатора становить 1 для Emploee_data і 100 для таблиці відділу.
Нарешті, ми виконуємо наведені нижче оператори, які відображають результат 100 для функції SELECT @@IDENTITY і 1 для функції SCOPE_IDENTITY, оскільки вони повертають значення ідентичності лише в тій самій області.
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
Ось результат:

Функція IDENT_CURRENT().
IDENT_CURRENT — це визначена системою функція для відобразити останнє значення IDENTITY згенерований для даної таблиці під будь-яким підключенням. Ця функція не враховує область SQL-запиту, який створює значення ідентифікатора. Для цієї функції потрібна назва таблиці, для якої ми хочемо отримати ідентифікаційне значення.
приклад
Ми можемо це зрозуміти, спочатку відкривши два вікна підключення. Ми вставимо один запис у перше вікно, яке генерує значення ідентичності 15 у таблиці person. Далі ми можемо перевірити це значення ідентичності в іншому вікні підключення, де ми можемо побачити той самий результат. Ось повний код:
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
Виконання наведених вище кодів у двох різних вікнах відобразить однакове значення ідентифікатора.

Функція IDENTITY().
Функція IDENTITY() є системною функцією використовується для вставки стовпця ідентичності в нову таблицю . Ця функція відрізняється від властивості IDENTITY, яку ми використовуємо з операторами CREATE TABLE і ALTER TABLE. Ми можемо використовувати цю функцію лише в операторі SELECT INTO, який використовується під час перенесення даних з однієї таблиці в іншу.
Наступний синтаксис ілюструє використання цієї функції в SQL Server:
IDENTITY (data_type , seed , increment) AS column_name
Якщо вихідна таблиця має стовпець IDENTITY, таблиця, сформована за допомогою команди SELECT INTO, успадковує його за замовчуванням. Наприклад , ми раніше створили таблицю person зі стовпцем ідентифікатора. Припустімо, ми створюємо нову таблицю, яка успадковує таблицю person за допомогою операторів SELECT INTO з функцією IDENTITY(). У цьому випадку ми отримаємо повідомлення про помилку, оскільки вихідна таблиця вже має стовпець ідентичності. Перегляньте запит нижче:
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
Виконання наведеного вище оператора поверне таке повідомлення про помилку:

Давайте створимо нову таблицю без властивості identity за допомогою наведеного нижче оператора:
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
Потім скопіюйте цю таблицю за допомогою оператора SELECT INTO, включаючи функцію IDENTITY, як показано нижче:
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
Після виконання оператора ми можемо перевірити його за допомогою sp_help команда, яка відображає властивості таблиці.

Ви можете побачити стовпець IDENTITY у СПОКАСНІ властивості відповідно до зазначених умов.
Якщо ми використовуємо цю функцію з інструкцією SELECT, SQL Server видасть таке повідомлення про помилку:
Повідомлення 177, рівень 15, стан 1, рядок 2. Функцію IDENTITY можна використовувати лише тоді, коли оператор SELECT має речення INTO.
Повторне використання значень IDENTITY
Ми не можемо повторно використовувати значення ідентичності в таблиці SQL Server. Коли ми видаляємо будь-який рядок із таблиці стовпців ідентифікаційних даних, у стовпці ідентифікаційних даних буде створено прогалину. Крім того, SQL Server створить прогалину, коли ми вставимо новий рядок у стовпець ідентичності, і оператор не вдасться або буде відкочено. Проміжок вказує на те, що ідентифікаційні значення втрачено та не можуть бути згенеровані знову в стовпці IDENTITY.
Розгляньте наведений нижче приклад, щоб зрозуміти його практично. У нас уже є таблиця осіб, яка містить такі дані:

Далі ми створимо ще дві таблиці з іменами 'позиція' і ' person_position ' використовуючи такий оператор:
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
Далі ми намагаємося вставити новий запис у таблицю person і призначити їм позицію, додавши новий рядок у таблицю person_position. Ми зробимо це за допомогою заяви про транзакцію, як показано нижче:
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
Наведений вище сценарій коду транзакції успішно виконує перший оператор вставки. Але другий оператор не вдався, оскільки в таблиці позицій не було позиції з ідентифікатором десять. Таким чином, усю транзакцію було скасовано.
Оскільки максимальне значення ідентифікатора в стовпці PersonID дорівнює 16, перший оператор вставки використав значення ідентифікатора 17, а потім транзакцію було відкочено. Отже, якщо ми вставимо наступний рядок у таблицю Person, наступне значення ідентичності буде 18. Виконайте наведений нижче оператор:
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
Після повторної перевірки таблиці person ми бачимо, що щойно доданий запис містить ідентифікаційне значення 18.

Два стовпці IDENTITY в одній таблиці
Технічно неможливо створити два стовпці ідентичності в одній таблиці. Якщо ми це зробимо, SQL Server видасть помилку. Перегляньте наступний запит:
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
Коли ми виконаємо цей код, ми побачимо таку помилку:

Однак ми можемо створити два стовпці ідентичності в одній таблиці за допомогою обчисленого стовпця. Наступний запит створює таблицю з обчисленим стовпцем, який використовує вихідний стовпець ідентичності та зменшує його на 1.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
Далі ми додамо деякі дані в цю таблицю за допомогою наведеної нижче команди:
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
Нарешті, ми перевіряємо дані таблиці за допомогою оператора SELECT. Він повертає такий результат:

Ми бачимо на зображенні, як стовпець SecondID діє як другий стовпець ідентичності, зменшуючись на десять від початкового значення 9990.
Помилкові уявлення про стовпець IDENTITY SQL Server
Користувач DBA має багато неправильних уявлень щодо стовпців ідентичності SQL Server. Нижче наведено список найпоширеніших помилок щодо стовпців ідентичності, які можна побачити:
Стовпець IDENTITY є УНІКАЛЬНИМ: Відповідно до офіційної документації SQL Server властивість identity не може гарантувати унікальність значення стовпця. Ми повинні використовувати PRIMARY KEY, обмеження UNIQUE або індекс UNIQUE, щоб забезпечити унікальність стовпця.
Стовпець IDENTITY генерує послідовні числа: В офіційній документації чітко зазначено, що присвоєні значення в стовпці ідентифікації можуть бути втрачені у разі збою бази даних або перезапуску сервера. Це може спричинити прогалини в ідентифікаційному значенні під час вставки. Проміжок також може виникнути, коли ми видаляємо значення з таблиці або виконується відкат оператора вставки. Значення, які створюють пропуски, не можна використовувати далі.
Стовпець IDENTITY не може автоматично генерувати наявні значення: Стовпець ідентифікаційних даних не може автоматично генерувати наявні значення, доки властивість ідентифікаційних даних не буде повторно заповнено за допомогою команди DBCC CHECKIDENT. Це дозволяє нам налаштувати початкове значення (початкове значення рядка) властивості ідентифікації. Після виконання цієї команди SQL Server не буде перевіряти новостворені значення, які вже присутні в таблиці, чи ні.
Для ідентифікації рядка достатньо стовпця IDENTITY як ПЕРВИННОГО КЛЮЧА: Якщо первинний ключ містить ідентифікаційний стовпець у таблиці без будь-яких інших унікальних обмежень, стовпець може зберігати повторювані значення та запобігати унікальності стовпця. Як ми знаємо, первинний ключ не може зберігати повторювані значення, але стовпець ідентичності може зберігати дублікати; не рекомендується використовувати первинний ключ і властивість ідентичності в одному стовпці.
Використання неправильного інструменту для повернення значень ідентичності після вставки: Також поширеною помилкою є незнання відмінностей між функціями @@IDENTITY, SCOPE_IDENTITY(), IDENT_CURRENT і IDENTITY(), щоб отримати значення ідентифікатора, безпосередньо вставлене з оператора, який ми щойно виконали.
Різниця між SEQUENCE та IDENTITY
Ми використовуємо SEQUENCE та IDENTITY для створення автоматичних номерів. Однак він має деякі відмінності, і головна відмінність полягає в тому, що ідентичність залежить від таблиці, тоді як послідовність – ні. Узагальнимо їх відмінності в табличній формі:
| ІДЕНТИЧНІСТЬ | ПОСЛІДОВНІСТЬ |
|---|---|
| Властивість ідентичності використовується для певної таблиці, і її не можна спільно використовувати з іншими таблицями. | Адміністратор бази даних визначає об’єкт послідовності, який може бути спільним для кількох таблиць, оскільки він не залежить від таблиці. |
| Ця властивість автоматично генерує значення кожного разу, коли оператор вставки виконується в таблиці. | Він використовує речення NEXT VALUE FOR, щоб створити наступне значення для об’єкта послідовності. |
| SQL Server не скидає значення стовпця властивості ідентифікації до початкового значення. | SQL Server може скинути значення для об’єкта послідовності. |
| Ми не можемо встановити максимальне значення властивості ідентифікації. | Ми можемо встановити максимальне значення для об’єкта послідовності. |
| Він представлений у SQL Server 2000. | Він представлений у SQL Server 2012. |
| Ця властивість не може генерувати значення ідентифікатора в порядку зменшення. | Він може генерувати значення в порядку зменшення. |
Висновок
У цій статті надано повний огляд властивості IDENTITY у SQL Server. Тут ми дізналися, як і коли використовується властивість ідентичності, її різні функції, неправильні уявлення та чим вона відрізняється від послідовності.