Команда Linux uniq використовується для видалення всіх повторюваних рядків із файлу. Крім того, його можна використовувати для відображення кількості будь-яких слів, лише повторюваних рядків, ігнорування символів і порівняння певних полів. Це одна з найбільш часто використовуваних команд у Linux система. Його часто використовують з команда сортування тому що він порівнює сусідні символи. Він відкидає всі ідентичні рядки та записує результат.
Синтаксис:
uniq [OPTION]... [INPUT [OUTPUT]]
Опції:
Деякі корисні параметри командного рядка команди uniq:
-c, --count: він префіксує рядки за кількістю входжень.
-d, --повторюється: він використовується для друку дублікатів рядків, по одному для кожної групи.
-Д: Він використовується для друку всіх повторюваних рядків.
--all-repeated[=МЕТОД]: Це дуже схоже на параметр '-D', відмінність між двома параметрами полягає в тому, що він дозволяє розділяти групи порожнім рядком.
підкреслити за допомогою css
-f, --skip-fields=N: Він використовується, щоб уникнути порівняння перших N полів.
--group[=МЕТОД]: Він використовується для відображення всіх елементів і відокремлює групи порожнім рядком.
-i, --ігнорувати регістр: Він використовується для ігнорування відмінностей під час порівняння.
-s, --skip-chars=N: Він використовується, щоб уникнути порівняння перших N символів.
-u, --унікальний: він використовується для друку унікальних ліній.
-z, --закінчується нулем: Він використовується для того, щоб роздільник рядків був NUL, а не в режимі нового рядка.
-w, --check-chars=N: Використовується для порівняння не більше N символів у рядках.
--довідка: Він використовується для відображення довідкової документації.
--версія: Він використовується для відображення інформації про версію.
Приклади команди uniq
Давайте розглянемо наступні приклади команди uniq:
- Видалити повторювані рядки
- підрахувати кількість входжень слова
- Відображення рядків, що повторюються
- Відображення унікальних ліній
- Ігнорувати символи в порівнянні
- Ігнорувати поля при порівнянні
Видалити повторювані рядки
Щоб видалити повторювані рядки з файлу, виконайте базову команду uniq таким чином:
sort dupli.txt | uniq
Наведена вище команда видалить повторювані рядки з файлу 'dupli.txt'. Розглянемо наведений нижче результат:
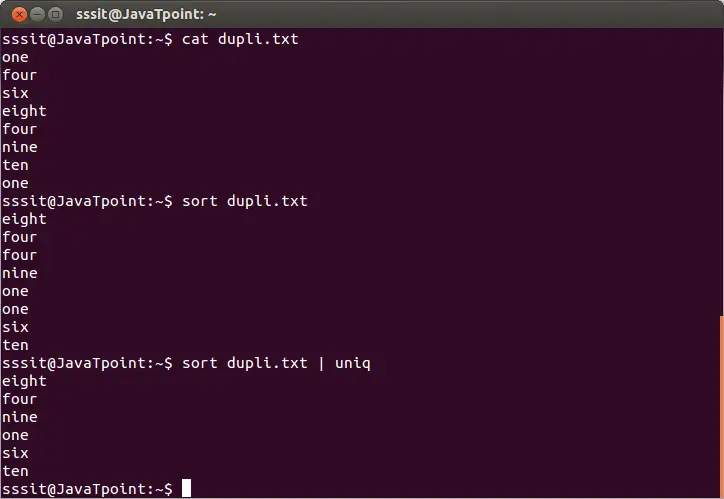
З наведеного вище виводу слова, що повторюються, ігноруються.
Підрахуйте кількість входжень слова
Ми можемо підрахувати кількість входжень слова за допомогою команди uniq. Опція '-c' використовується для підрахунку слова. Виконайте його так:
sort dupli.txt | uniq -c
Наведена вище команда рахуватиме слова, які надходять у 'dupli.txt'. Розглянемо наведений нижче результат:

З наведеного вище результату команда 'sort dupli.txt | uniq -c' підраховує кількість повторів слова.
Відображення рядків, що повторюються
Параметр '-d' використовується для відображення лише повторюваних рядків. Він відображатиме лише рядки, які будуть більше одного разу у файлі, і записуватиме вихідні дані у стандартний вивід. Розглянемо наведену нижче команду:
sort dupli.txt | uniq -d
Наведена вище команда відображатиме лише повторювані рядки. Розглянемо наведений нижче результат:

Відображення унікальних ліній
Параметр '-u' використовується для відображення лише унікальних рядків (які не повторюються). Він відображатиме лише ті рядки, які трапляються лише один раз, і записуватиме результат у стандартний вивід. Розглянемо наведену нижче команду:
sort dupli.txt | uniq -u
Наведена вище команда відображатиме лише унікальні рядки з файлу 'dupli.txt'. Розглянемо наведений нижче результат:

Ігнорувати символи в порівнянні
Параметр '-s' використовується для ігнорування символів у порівнянні. Він проігнорує вказану кількість символів і виведе результат у стандартний вивід. Розглянемо наведену нижче команду:
sort dupli.txt | uniq -s 2
Наведена вище команда ігноруватиме перші два символи у порівнянні з файлом 'dupli.txt'. Розглянемо наведений нижче результат:

Ігнорувати поля при порівнянні
Параметр '-f' використовується для ігнорування полів. Розглянемо наведену нижче команду:
uniq -f 2 dupli2.txt
Наведена вище команда не порівнюватиме перші два поля з файлу 'dupli2.txt'. Розглянемо наведений нижче результат:

У наведеному вище виводі перші два поля пропускаються, а решта всіх полів порівнюється з файлу 'dupli2.txt'.