Наступна архітектура пояснює потік подання запиту до Hive.
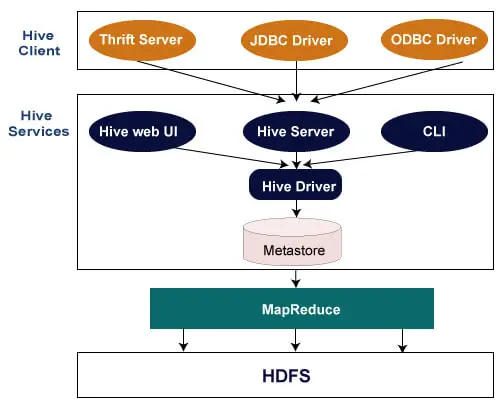
Клієнт Hive
Hive дозволяє писати програми різними мовами, включаючи Java, Python і C++. Він підтримує різні типи клієнтів, такі як:-
- Thrift Server – це міжмовна платформа постачальника послуг, яка обслуговує запити від усіх тих мов програмування, які підтримують Thrift.
- Драйвер JDBC - використовується для встановлення зв'язку між вуликом і програмами Java. Драйвер JDBC присутній у класі org.apache.hadoop.hive.jdbc.HiveDriver.
- Драйвер ODBC - дозволяє програмам, які підтримують протокол ODBC, підключатися до Hive.
Служби Hive
Hive надає такі послуги:
- Hive CLI. Hive CLI (інтерфейс командного рядка) — це оболонка, у якій ми можемо виконувати запити та команди Hive.
- Веб-інтерфейс користувача Hive. Інтерфейс веб-користувача Hive є лише альтернативою Hive CLI. Він надає графічний веб-інтерфейс для виконання запитів і команд Hive.
- Hive MetaStore - це центральне сховище, яке зберігає всю інформацію про структуру різних таблиць і розділів у складі. Він також містить метадані стовпця та інформацію про його тип, серіалізатори та десеріалізатори, які використовуються для читання та запису даних, і відповідні файли HDFS, де зберігаються дані.
- Hive Server - він називається Apache Thrift Server. Він приймає запит від різних клієнтів і надає його Hive Driver.
- Hive Driver – він отримує запити з різних джерел, таких як веб-інтерфейс користувача, CLI, Thrift і драйвер JDBC/ODBC. Він передає запити компілятору.
- Компілятор Hive. Метою компілятора є аналіз запиту та виконання семантичного аналізу різних блоків і виразів запиту. Він перетворює оператори HiveQL на завдання MapReduce.
- Hive Execution Engine – Optimizer генерує логічний план у формі DAG із завдань зменшення карти та завдань HDFS. Зрештою, механізм виконання виконує вхідні завдання в порядку їх залежностей.