БЕРТ, акронім для представлень двонаправленого кодера від Transformers , виступає як відкритий код структура машинного навчання призначений для сфери обробка природної мови (NLP) . Цей фреймворк, що виник у 2018 році, створили дослідники Google AI Language. Стаття спрямована на дослідження архітектура, робота та застосування BERT .
Що таке BERT?
BERT (Подання двонаправленого кодера від трансформаторів) використовує трансформаторну нейронну мережу для розуміння та створення людської мови. BERT використовує архітектуру лише кодера. В оригіналі Трансформаторна архітектура , є модулі кодера та декодера. Рішення використовувати архітектуру лише кодера в BERT передбачає основний акцент на розумінні вхідних послідовностей, а не на генеруванні вихідних послідовностей.
Двонаправлений підхід BERT
Традиційні мовні моделі обробляють текст послідовно або зліва направо, або справа наліво. Цей метод обмежує обізнаність моделі безпосереднім контекстом перед цільовим словом. BERT використовує двонаправлений підхід, враховуючи як лівий, так і правий контексти слів у реченні, замість того, щоб аналізувати текст послідовно, BERT розглядає всі слова в реченні одночасно.
Приклад: берег розташований на _______ річці.
В односпрямованій моделі розуміння пропуску значною мірою залежатиме від попередніх слів, і моделі може бути важко розрізнити, чи банк стосується фінансової установи чи берега річки.
BERT, будучи двонаправленим, одночасно розглядає як лівий (берег розташований на березі), так і правий контекст (річки), що забезпечує більш детальне розуміння. Він розуміє, що відсутнє слово, ймовірно, пов’язане з географічним розташуванням банку, демонструючи контекстуальне багатство, яке приносить двонаправлений підхід.
Попереднє навчання та тонке налаштування
Модель BERT проходить двоетапний процес:
- Попереднє навчання великому об’єму тексту без міток для вивчення контекстних вставок.
- Точне налаштування позначених даних для конкретних НЛП завдання.
Попередня підготовка з великих даних
- BERT попередньо навчений на велику кількість текстових даних без міток. Модель вивчає контекстуальні вбудовування, які є представленнями слів, які враховують навколишній контекст у реченні.
- BERT виконує різноманітні завдання перед навчанням без нагляду. Наприклад, він може навчитися передбачати пропущені слова в реченні (завдання «Модель маскової мови» або MLM), розуміти зв’язок між двома реченнями або передбачати наступне речення в парі.
Точне налаштування позначених даних
- Після фази попереднього навчання модель BERT, озброєна своїми контекстними вбудованими компонентами, потім налаштовується для конкретних завдань обробки природної мови (NLP). Цей крок адаптує модель до більш цільових програм, адаптуючи її загальне розуміння мови до нюансів конкретного завдання.
- BERT налаштовується за допомогою позначених даних, специфічних для наступних завдань, що цікавлять. Ці завдання можуть включати аналіз настроїв, відповіді на запитання, розпізнавання іменованої сутності або будь-який інший додаток NLP. Параметри моделі налаштовані для оптимізації її продуктивності для конкретних вимог поставленого завдання.
Уніфікована архітектура BERT дозволяє адаптувати його до різноманітних подальших завдань з мінімальними модифікаціями, що робить його універсальним і високоефективним інструментом у розуміння природної мови і обробки.
Як працює BERT?
BERT призначений для створення мовної моделі, тому використовується лише механізм кодування. Послідовність жетонів подається на кодер Transformer. Ці маркери спочатку вбудовуються у вектори, а потім обробляються в нейронній мережі. Вихід – це послідовність векторів, кожен з яких відповідає вхідному токенові, що забезпечує контекстуалізовані представлення.
Під час навчання мовних моделей визначення цілі передбачення є проблемою. Багато моделей передбачають наступне слово в послідовності, що є спрямованим підходом і може обмежити вивчення контексту. BERT вирішує цю проблему за допомогою двох інноваційних стратегій навчання:
- Модель маскової мови (MLM)
- Передбачення наступного речення (NSP)
1. Модель маскової мови (MLM)
У процесі попереднього навчання BERT частина слів у кожній вхідній послідовності маскується, а модель навчається передбачати вихідні значення цих замаскованих слів на основі контексту, наданого навколишніми словами.
Простіше кажучи,
- Маскувальні слова: Перш ніж BERT навчатиметься з речень, він приховує деякі слова (близько 15%) і замінює їх спеціальним символом, наприклад [МАСКА].
- Вгадування прихованих слів: Робота BERT полягає в тому, щоб з’ясувати, що це за приховані слова, дивлячись на слова навколо них. Це схоже на гру в здогадування пропущених слів, і BERT намагається заповнити пропуски.
- Як BERT навчається:
- BERT додає спеціальний рівень поверх своєї системи навчання, щоб зробити ці припущення. Потім він перевіряє, наскільки близькі його припущення до фактичних прихованих слів.
- Він робить це, перетворюючи свої припущення на ймовірності, кажучи: «Я думаю, що це слово X, і я настільки впевнений у цьому».
- Особлива увага до прихованих слів
- Основна увага BERT під час тренінгу зосереджена на правильному розумінні цих прихованих слів. Він менше піклується про передбачення слів, які не приховані.
- Це тому, що справжня проблема полягає в тому, щоб з’ясувати відсутні частини, і ця стратегія допомагає BERT справді добре розуміти значення та контекст слів.
З технічної точки зору,
- BERT додає класифікаційний рівень поверх вихідних даних із кодера. Цей рівень є вирішальним для передбачення замаскованих слів.
- Вихідні вектори з рівня класифікації множаться на матрицю вбудовування, перетворюючи їх у вимір словника. Цей крок допомагає узгодити передбачені представлення з простором словника.
- Імовірність кожного слова в словнику розраховується за допомогою Функція активації SoftMax . Цей крок генерує розподіл ймовірностей по всьому словнику для кожної замаскованої позиції.
- Функція втрат, яка використовується під час навчання, враховує лише передбачення замаскованих значень. Модель штрафується за відхилення між її прогнозами та фактичними значеннями замаскованих слів.
- Модель сходиться повільніше, ніж спрямовані моделі. Це пояснюється тим, що під час навчання BERT займається лише передбаченням замаскованих значень, ігноруючи передбачення незамаскованих слів. Підвищене усвідомлення контексту, досягнуте завдяки цій стратегії, компенсує повільнішу конвергенцію.
2. Передбачення наступного речення (NSP)
BERT передбачає, чи пов’язане друге речення з першим. Це робиться шляхом перетворення вихідних даних маркера [CLS] у вектор у формі 2×1 за допомогою рівня класифікації, а потім обчислення ймовірності того, чи друге речення слідує за першим за допомогою SoftMax.
- У процесі навчання BERT вчиться розуміти зв’язок між парами речень, передбачаючи, чи йде друге речення за першим у вихідному документі.
- 50% вхідних пар мають друге речення як наступне речення в оригінальному документі, а інші 50% мають випадково вибране речення.
- Щоб допомогти моделі розрізнити зв’язані та роз’єднані пари речень. Вхідні дані обробляються перед входом у модель:
- Маркер [CLS] вставляється на початку першого речення, а маркер [SEP] додається в кінці кожного речення.
- Вбудоване речення, яке вказує на речення A або речення B, додається до кожного токена.
- Позиційне вбудовування вказує на позицію кожного маркера в послідовності.
- BERT передбачає, чи пов’язане друге речення з першим. Це робиться шляхом перетворення вихідних даних маркера [CLS] у вектор у формі 2×1 за допомогою рівня класифікації, а потім обчислення ймовірності того, чи друге речення слідує за першим за допомогою SoftMax.
Під час навчання моделі BERT, Masked LM і Next Sentence Prediction навчаються разом. Модель спрямована на мінімізацію комбінованої функції втрат Masked LM і Next Sentence Prediction, що призводить до надійної моделі мови з розширеними можливостями розуміння контексту в реченнях і зв’язків між реченнями.
Навіщо тренувати Masked LM і Next Sentence Prediction разом?
Masked LM допомагає BERT зрозуміти контекст у реченні та Передбачення наступного речення допомагає BERT зрозуміти зв'язок або відношення між парами речень. Отже, навчання обох стратегій разом гарантує, що BERT вивчає широке та всебічне розуміння мови, фіксуючи як деталі в реченнях, так і потік між реченнями.
BERT Architectures
Архітектура BERT — це багатошаровий двонаправлений трансформаторний кодер, який дуже схожий на модель трансформатора. Трансформаторна архітектура – це мережа кодера-декодера, яка використовує самоувага на стороні кодера та увагу на стороні декодера.
- БЕРТБАЗАмає 1 2 шари в стеку Encoder а BERTВЕЛИКИЙмає 24 шари в стеку Encoder . Це більше, ніж архітектура Transformer, описана в оригінальній статті ( 6 шарів кодера ).
- Архітектури BERT (BASE і LARGE) також мають більші мережі прямого зв’язку (768 і 1024 прихованих одиниць відповідно), і більше уваги голови (12 і 16 відповідно) ніж архітектура Transformer, запропонована в оригінальній статті. Це містить 512 прихованих одиниць і 8 голів уваги .
- БЕРТБАЗАмістить 110M параметрів, а BERTВЕЛИКИЙмає 340M параметрів.

Архітектура BERT BASE і BERT LARGE.
Ця модель займає CLS спочатку вводиться маркер, потім за ним йде послідовність слів у якості вхідних даних. Тут CLS — це маркер класифікації. Потім він передає вхідні дані вищезазначеним шарам. Застосовується кожен шар самоувага і передає результат через мережу прямого зв’язку, а потім передає його наступному кодеру. Модель виводить вектор прихованого розміру ( 768 для BERT BASE). Якщо ми хочемо вивести класифікатор із цієї моделі, ми можемо взяти вихід, що відповідає токену CLS.
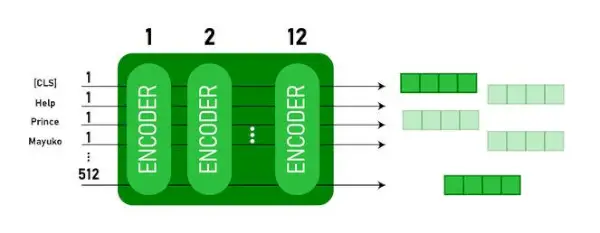
Вихід BERT як вбудовування
Тепер цей навчений вектор можна використовувати для виконання ряду завдань, таких як класифікація, переклад тощо. Наприклад, папір досягає чудових результатів лише за допомогою одного шару Нейронна мережа за моделлю BERT у класифікаційному завданні.
Як використовувати модель BERT в НЛП?
BERT можна використовувати для різних завдань обробки природної мови (NLP), таких як:
1. Класифікаційне завдання
- BERT можна використовувати для завдання класифікації, наприклад аналіз настроїв , мета полягає в тому, щоб класифікувати текст за різними категоріями (позитивний/негативний/нейтральний), BERT можна використовувати, додавши шар класифікації у верхній частині виводу Transformer для маркера [CLS].
- Маркер [CLS] представляє агреговану інформацію з усієї вхідної послідовності. Потім це об’єднане представлення можна використовувати як вхідні дані для рівня класифікації, щоб робити прогнози для конкретного завдання.
2. Відповідь на питання
- У завданнях із відповідями на питання, де від моделі вимагається знайти та позначити відповідь у певній текстовій послідовності, BERT можна навчити для цієї мети.
- BERT навчається відповідати на запитання, вивчаючи два додаткові вектори, які позначають початок і кінець відповіді. Під час навчання модель постачається питаннями та відповідними уривками, і вона вчиться передбачати початкову та кінцеву позиції відповіді в уривку.
3. Розпізнавання іменованих сутностей (NER)
- BERT можна використовувати для NER, де метою є ідентифікація та класифікація сутностей (наприклад, особа, організація, дата) у текстовій послідовності.
- Модель NER на основі BERT навчається шляхом отримання вихідного вектора кожного маркера з трансформатора та передачі його на рівень класифікації. Рівень передбачає іменовану мітку сутності для кожного маркера, вказуючи тип сутності, яку він представляє.
Як токенізувати та кодувати текст за допомогою BERT?
Для токенізації та кодування тексту за допомогою BERT ми будемо використовувати бібліотеку «transformer» у Python.
Команда для встановлення трансформаторів:
!pip install transformers>
- Ми завантажимо попередньо підготовлену токенізацію BERT за допомогою словника з регістром BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(текст) токенізує введений текст і перетворює його на послідовність ідентифікаторів маркерів.
- print(Ідентифікатори маркерів:, кодування) друкує ідентифікатори токенів, отримані після кодування.
- tokenizer.convert_ids_to_tokens(кодування) перетворює ідентифікатори маркерів назад у відповідні маркери.
- print(Tokens:, tokens) друкує маркери, отримані після перетворення ідентифікаторів маркерів
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Вихід:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> The tokenizer.encode метод додає спец [CLS] – класифікація і [SEP] – роздільник маркери на початку та в кінці закодованої послідовності.
Застосування BERT
BERT використовується для:
- Подання тексту: BERT використовується для створення вставок слів або представлення слів у реченні.
- Розпізнавання іменованих сутностей (NER) : BERT можна налаштувати для завдань розпізнавання іменованих об’єктів, метою яких є ідентифікація таких об’єктів, як імена людей, організацій, місцеположення тощо, у певному тексті.
- Класифікація тексту: BERT широко використовується для завдань класифікації тексту, включаючи аналіз настроїв, виявлення спаму та категоризацію тем. Він продемонстрував чудову продуктивність у розумінні та класифікації контексту текстових даних.
- Системи запитань-відповідей: BERT було застосовано до систем відповідей на запитання, де модель навчена розуміти контекст запитання та надавати відповідні відповіді. Це особливо корисно для таких завдань, як розуміння прочитаного.
- Машинний переклад: Контекстні вбудовані засоби BERT можна використовувати для вдосконалення систем машинного перекладу. Модель вловлює нюанси мови, які є вирішальними для точного перекладу.
- Резюмування тексту: BERT можна використовувати для абстрактного резюмування тексту, де модель генерує стислі та змістовні резюме довших текстів, розуміючи контекст і семантику.
- Розмовний ШІ: BERT використовується для створення розмовних систем ШІ, таких як чат-боти, віртуальні помічники та діалогові системи. Його здатність сприймати контекст робить його ефективним для розуміння та створення природних мовних відповідей.
- Семантична подібність: Вбудовування BERT можна використовувати для вимірювання семантичної подібності між реченнями або документами. Це корисно для таких завдань, як виявлення дублікатів, ідентифікація перефразування та пошук інформації.
BERT проти GPT
Різниця між BERT і GPT полягає в наступному:
| БЕРТ | GPT | |
|---|---|---|
| Архітектура | BERT розроблено для вивчення двонаправленого представлення. Він використовує замасковану ціль моделі мови, де передбачає пропущені слова в реченні на основі як лівого, так і правого контексту. | GPT, з іншого боку, призначений для генеративного моделювання мови. Він передбачає наступне слово в реченні з огляду на попередній контекст, використовуючи односпрямований авторегресійний підхід. |
| Цілі попереднього навчання | BERT попередньо навчений за допомогою цільової моделі замаскованої мови та передбачення наступного речення. Він зосереджений на захопленні двонаправленого контексту та розумінні зв’язків між словами в реченні. | GPT попередньо навчений передбачати наступне слово в реченні, що спонукає модель вивчати зв’язне представлення мови та генерувати контекстуально відповідні послідовності. |
| Розуміння контексту | BERT ефективний для завдань, які вимагають глибокого розуміння контексту та зв’язків у реченні, таких як класифікація тексту, розпізнавання іменованих об’єктів і відповіді на запитання. | GPT сильний у створенні зв’язного та релевантного тексту. Його часто використовують у творчих завданнях, діалогових системах і завданнях, що вимагають генерації послідовностей природної мови. |
| Типи завдань і випадки використання
| Зазвичай використовується в таких завданнях, як класифікація тексту, розпізнавання іменованих об’єктів, аналіз настроїв і відповіді на запитання. | Застосовується до таких завдань, як створення тексту, діалогові системи, конспектування та творче письмо. |
| Тонке налаштування проти короткочасного навчання | BERT часто точно налаштовується на конкретні наступні завдання з позначеними даними, щоб адаптувати свої попередньо підготовлені представлення до поточного завдання. | GPT розроблено для виконання нетривалого навчання, де його можна узагальнити для нових завдань з мінімальними навчальними даними для конкретних завдань. |
Також перевірте:
- Класифікація настрою за допомогою BERT
- Як створити Word Embedding за допомогою BERT?
- Модель BART для автоматичного завершення тексту в НЛП
- Класифікація токсичних коментарів за допомогою BERT
- Передбачення наступного речення за допомогою BERT
Часті запитання (FAQ)
Q. Для чого використовується BERT?
BERT використовується для виконання завдань NLP, таких як представлення тексту, розпізнавання іменованих об’єктів, класифікація тексту, системи запитань і відповідей, машинний переклад, узагальнення тексту тощо.
Q. Які переваги моделі BERT?
Мовна модель BERT виділяється завдяки широкому попередньому навчанню багатьма мовами, що пропонує широке лінгвістичне охоплення порівняно з іншими моделями. Це робить BERT особливо вигідним для неангломовних проектів, оскільки він забезпечує надійне контекстне представлення та семантичне розуміння в різноманітних мовах, підвищуючи його універсальність у багатомовних програмах.
Q. Як BERT працює для аналізу настроїв?
BERT чудово підходить для аналізу настроїв, використовуючи своє навчання двонаправленого представлення для вловлювання контекстуальних нюансів, семантичних значень і синтаксичних структур у певному тексті. Це дає змогу BERT зрозуміти настрої, виражені в реченні, враховуючи зв’язки між словами, що призводить до високоефективних результатів аналізу настроїв.
центрування зображення в css
Q. Google базується на BERT?
БЕРТ і RankBrain є компонентами пошукового алгоритму Google для обробки запитів і вмісту веб-сторінок для кращого розуміння та покращення результатів пошуку.