Що таке список пропусків?
Список пропусків — це імовірнісна структура даних. Список пропусків використовується для зберігання відсортованого списку елементів або даних зі зв’язаним списком. Це дозволяє ефективно переглядати процес елементів або даних. За один крок він пропускає кілька елементів усього списку, тому його називають списком пропуску.
Список пропусків є розширеною версією пов’язаного списку. Це дозволяє користувачеві дуже швидко шукати, видаляти та вставляти елемент. Він складається з базового списку, який включає набір елементів, який підтримує ієрархію посилань наступних елементів.
Структура списку пропусків
Він складається з двох шарів: нижнього та верхнього.
Найнижчий рівень списку пропусків є звичайним відсортованим пов’язаним списком, а верхні шари списку пропусків схожі на «швидку лінію», де елементи пропускаються.
Таблиця складності списку пропусків
| Так ні | Складність | Середній випадок | Найгірший випадок |
|---|---|---|---|
| 1. | Складність доступу | O (вхід) | O(n) |
| 2. | Складність пошуку | O (вхід) | O(n) |
| 3. | Видалити складність | O (вхід) | O(n) |
| 4. | Складність вставки | O (вхід) | O(n) |
| 5. | Космічна складність | - | O (nlogn) |
Робота списку пропусків
Розглянемо приклад, щоб зрозуміти, як працює список пропусків. У цьому прикладі ми маємо 14 вузлів, які розділені на два шари, як показано на схемі.
Нижній рівень — це загальна лінія, яка з’єднує всі вузли, а верхній — швидка лінія, яка з’єднує лише основні вузли, як ви можете бачити на схемі.
Припустимо, ви хочете знайти 47 у цьому прикладі. Ви почнете пошук із першого вузла експрес-лінії та продовжите рух по експрес-лінії, доки не знайдете вузол, який дорівнює 47 або перевищує 47.
У прикладі ви бачите, що 47 не існує в експрес-рядку, тому ви шукаєте вузол менше 47, тобто 40. Тепер ви переходите до звичайного рядка за допомогою 40 і шукаєте 47, як показано на схемі.
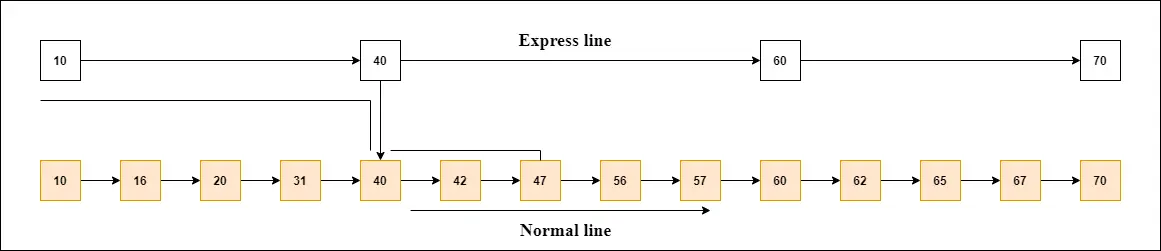
Примітка. Коли ви знайдете такий вузол на «швидкісній лінії», ви переходите з цього вузла на «звичайну смугу» за допомогою вказівника, а коли ви шукаєте вузол на звичайній лінії.
Пропустити список основних операцій
У списку пропуску є наступні типи операцій.
Алгоритм операції вставки
Insertion (L, Key) local update [0...Max_Level + 1] a = L → header for i = L → level down to 0 do. while a → forward[i] → key forward[i] update[i] = a a = a → forward[0] lvl = random_Level() if lvl > L → level then for i = L → level + 1 to lvl do update[i] = L → header L → level = lvl a = makeNode(lvl, Key, value) for i = 0 to level do a → forward[i] = update[i] → forward[i] update[i] → forward[i] = a
Алгоритм операції видалення
Deletion (L, Key) local update [0... Max_Level + 1] a = L → header for i = L → level down to 0 do. while a → forward[i] → key forward[i] update[i] = a a = a → forward[0] if a → key = Key then for i = 0 to L → level do if update[i] → forward[i] ? a then break update[i] → forward[i] = a → forward[i] free(a) while L → level > 0 and L → header → forward[L → level] = NIL do L → level = L → level - 1
Алгоритм пошукової операції
Searching (L, SKey) a = L → header loop invariant: a → key level down to 0 do. while a → forward[i] → key forward[i] a = a → forward[0] if a → key = SKey then return a → value else return failure
приклад 1: Створіть список пропусків, ми хочемо вставити наступні ключі в порожній список пропусків.
- 6 з рівнем 1.
- 29 з рівнем 1.
- 22 з 4 рівнем.
- 9 з рівнем 3.
- 17 з рівнем 1.
- 4 з рівнем 2.
років:
Крок 1: Вставте 6 із рівнем 1

крок 2: Вставте 29 із рівнем 1

крок 3: Вставте 22 із рівнем 4

крок 4: Вставте 9 із рівнем 3

крок 5: Вставте 17 із рівнем 1

Крок 6: Вставте 4 з рівнем 2

приклад 2: Розглянемо цей приклад, де ми хочемо шукати ключ 17.

років:

Переваги Skip list
- Якщо ви хочете вставити новий вузол у список пропусків, вузол буде вставлено дуже швидко, оскільки в списку пропусків немає поворотів.
- Список пропусків простий у реалізації порівняно з хеш-таблицею та бінарним деревом пошуку.
- Знайти вузол у списку дуже просто, оскільки він зберігає вузли у відсортованому вигляді.
- Алгоритм списку пропусків можна дуже легко модифікувати в більш специфічній структурі, такій як індексовані списки пропусків, дерева або черги пріоритетів.
- Список пропусків — надійний і надійний список.
Недоліки списку пропусків
- Для цього потрібно більше пам’яті, ніж для збалансованого дерева.
- Зворотний пошук заборонено.
- Список пропусків шукає вузол набагато повільніше, ніж пов’язаний список.
Застосування списку пропуску
- Він використовується в розподілених програмах і представляє покажчики та систему в розподілених програмах.
- Він використовується для реалізації динамічної еластичної паралельної черги з низьким рівнем конкуренції за блокування.
- Він також використовується з класом шаблону QMap.
- Індексація списку пропусків використовується при виконанні медіанних задач.
- Список пропусків використовується для публікації дельта-кодування в пошуку Lucene.