- dnorm()
dnorm(x, mean, sd)>pnorm()
pnorm(x, mean, sd)>qnorm()
qnorm(p, mean, sd)>rnorm()
rnorm(n, mean, sd)>де,
– x представляє набір даних значень – середнє (x) представляє середнє значення набору даних x . Значення за умовчанням дорівнює 0.>– sd(x) являє собою стандартне відхилення набору даних x . Значення за умовчанням дорівнює 1.>– п – кількість спостережень. – стор є вектором ймовірностей
Функції для створення нормального розподілу в R
dnorm()
dnorm()> функція в програмуванні R вимірює функцію щільності розподілу. У статистиці він вимірюється за наведеною нижче формулою:>де,
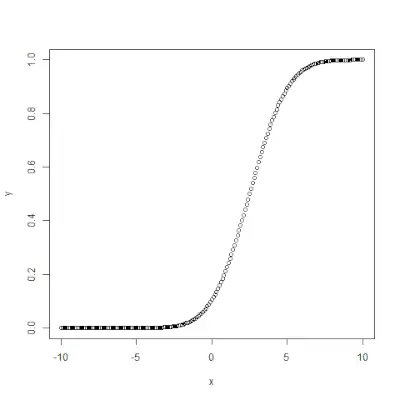
 означає і
означає і 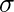 є стандартним відхиленням. Синтаксис:
є стандартним відхиленням. Синтаксис: dnorm(x, mean, sd)>приклад:
# creating a sequence of values> # between -15 to 15 with a difference of 0.1> x>=> seq(>->15>,>15>, by>=>0.1>)> > y>=> dnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file>=>'dnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Вихід:
pnorm()
pnorm()> функція — це інтегральна функція розподілу, яка вимірює ймовірність того, що випадкове число X приймає значення, менше або дорівнює x, тобто в статистиці вона визначається як>Синтаксис:
pnorm(x, mean, sd)>приклад:
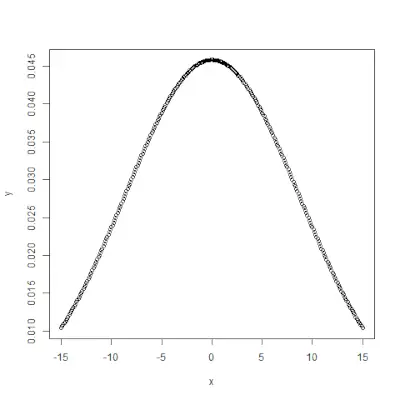
# creating a sequence of values> # between -10 to 10 with a difference of 0.1> x <>-> seq(>->10>,>10>, by>=>0.1>)> > y <>-> pnorm(x, mean>=> 2.5>, sd>=> 2>)> > # output to be present as PNG file> png(>file>=>'pnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Вихід:
qnorm()
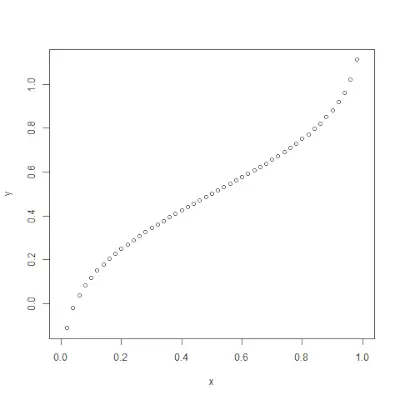
qnorm()> функція є зворотною до pnorm()>функція. Він приймає значення ймовірності та видає вихід, який відповідає значенню ймовірності. Це корисно для знаходження процентилів нормального розподілу. Синтаксис: qnorm(p, mean, sd)>приклад:
# Create a sequence of probability values> # incrementing by 0.02.> x <>-> seq(>0>,>1>, by>=> 0.02>)> > y <>-> qnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file> => 'qnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # Save the file.> dev.off()> |
>
>Вихід:
rnorm()
rnorm()> Функція в програмуванні R використовується для генерації вектора випадкових чисел, які розподілені нормально. Синтаксис: rnorm(x, mean, sd)>приклад:
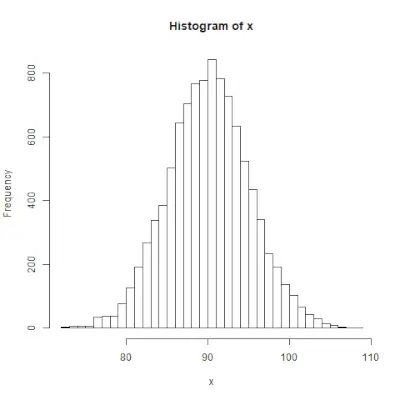
# Create a vector of 1000 random numbers> # with mean=90 and sd=5> x <>-> rnorm(>10000>, mean>=>90>, sd>=>5>)> > # output to be present as PNG file> png(>file> => 'rnormExample.webp'>)> > # Create the histogram with 50 bars> hist(x, breaks>=>50>)> > # Save the file.> dev.off()> |
>
>Вихід: