А Згорточна нейронна мережа (CNN) це тип архітектури нейронної мережі Deep Learning, який зазвичай використовується в Computer Vision. Комп’ютерний зір – це сфера штучного інтелекту, яка дозволяє комп’ютеру розуміти та інтерпретувати зображення або візуальні дані.
структури даних в java
Що стосується машинного навчання, Штучні нейронні мережі справді добре. Нейронні мережі використовуються в різних наборах даних, таких як зображення, аудіо та текст. Різні типи нейронних мереж використовуються для різних цілей, наприклад, для передбачення послідовності слів, які ми використовуємо Рекурентні нейронні мережі точніше ан LSTM , так само для класифікації зображень ми використовуємо згорточні нейронні мережі. У цьому блозі ми збираємося створити базовий будівельний блок для CNN.
У звичайній нейронній мережі є три типи шарів:
- Вхідні шари: Це шар, на якому ми вводимо дані для нашої моделі. Кількість нейронів у цьому шарі дорівнює загальній кількості ознак у наших даних (кількості пікселів у випадку зображення).
- Прихований шар: Потім вхідні дані з вхідного шару надходять у прихований шар. Може бути багато прихованих шарів залежно від нашої моделі та розміру даних. Кожен прихований шар може мати різну кількість нейронів, яка, як правило, перевищує кількість функцій. Вихідні дані кожного шару обчислюються шляхом множення матриці вихідних даних попереднього шару на вагові коефіцієнти цього шару, які можна дізнатися, а потім шляхом додавання зміщень, які можна дізнатися, з наступною функцією активації, яка робить мережу нелінійною.
- Вихідний рівень: Вихідні дані з прихованого шару потім подаються в логістичну функцію, наприклад sigmoid або softmax, яка перетворює вихідні дані кожного класу в оцінку ймовірності кожного класу.
Дані вводяться в модель, і вихідні дані з кожного шару, отримані з описаного вище кроку, називаються передавання , потім ми обчислюємо похибку за допомогою функції похибок, деякі поширені функції похибок — крос-ентропія, похибка квадратичних втрат тощо. Функція похибок вимірює, наскільки добре працює мережа. Після цього ми повертаємося до моделі шляхом обчислення похідних. Цей крок називається Згорточна нейронна мережа (CNN) є розширеною версією штучні нейронні мережі (ШНМ) який переважно використовується для вилучення функції з набору даних матриці у вигляді сітки. Наприклад, візуальні набори даних, такі як зображення чи відео, де шаблони даних відіграють велику роль.
Архітектура CNN
Згортка нейронної мережі складається з кількох рівнів, таких як вхідний рівень, згортковий рівень, рівень об’єднання та повністю зв’язані рівні.

Проста архітектура CNN
Згортковий рівень застосовує фільтри до вхідного зображення, щоб виділити особливості, рівень об’єднання зменшує дискретизацію зображення, щоб зменшити обчислення, а повністю підключений рівень робить остаточний прогноз. Мережа вивчає оптимальні фільтри за допомогою зворотного поширення та градієнтного спуску.
Як працює згортковий шар
Нейронні мережі згортки або ковнети — це нейронні мережі, які мають спільні параметри. Уявіть, що у вас є образ. Його можна представити у вигляді прямокутної форми, яка має довжину, ширину (розмір зображення) і висоту (тобто канал, оскільки зображення зазвичай мають червоні, зелені та сині канали).
угода про імена java
А тепер уявіть, що ви берете невеликий фрагмент цього зображення та запускаєте на ньому невелику нейронну мережу, яка називається фільтром або ядром, із, скажімо, K виходами та представляючи їх вертикально. Тепер проведіть цією нейронною мережею по всьому зображенню, в результаті ми отримаємо інше зображення з різною шириною, висотою та глибиною. Замість лише каналів R, G та B тепер у нас більше каналів, але менша ширина та висота. Ця операція називається згортка . Якщо розмір патча такий самий, як і зображення, це буде звичайна нейронна мережа. Через цей маленький фрагмент у нас менше ваги.
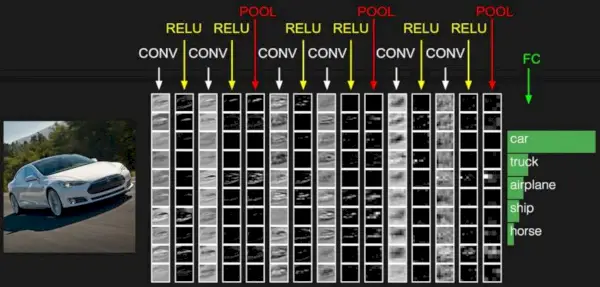
Джерело зображення: Deep Learning Udacity
Тепер давайте трохи поговоримо про математику, яка бере участь у всьому процесі згортки.
- Згорткові шари складаються з набору доступних для навчання фільтрів (або ядер), які мають малу ширину та висоту та таку саму глибину, що й у вхідного об’єму (3, якщо вхідний рівень є вхідним зображенням).
- Наприклад, якщо нам потрібно запустити згортку на зображенні розміром 34x34x3. Можливий розмір фільтрів може бути axax3, де «a» може мати значення 3, 5 або 7, але менше порівняно з розміром зображення.
- Під час прямого проходу ми крок за кроком пересуваємо кожен фільтр по всьому вхідному об’єму, де викликається кожен крок крокувати (яке може мати значення 2, 3 або навіть 4 для високорозмірних зображень) і обчислити скалярний добуток між вагами ядра та патчем на основі вхідного обсягу.
- Коли ми пересуваємо наші фільтри, ми отримаємо 2-D вихід для кожного фільтра, і ми складемо їх разом, як результат, ми отримаємо вихідний об’єм, глибина якого дорівнює кількості фільтрів. Мережа дізнається всі фільтри.
Шари, які використовуються для побудови ConvNets
Повна архітектура згорткових нейронних мереж також відома як ковнети. Ковнети — це послідовність шарів, і кожен шар перетворює один об’єм на інший за допомогою диференційованої функції.
Типи шарів: набори даних
Давайте візьмемо приклад, запустивши ковнет на зображенні розміром 32 x 32 x 3.
- Вхідні шари: Це шар, на якому ми вводимо дані для нашої моделі. У CNN, як правило, введенням буде зображення або послідовність зображень. Цей шар містить необроблені вхідні дані зображення з шириною 32, висотою 32 і глибиною 3.
- Згорткові шари: Це шар, який використовується для вилучення об’єкта з вхідного набору даних. Він застосовує набір фільтрів, які можна вивчати, відомих як ядра, до вхідних зображень. Фільтри/ядра — це менші матриці, зазвичай 2×2, 3×3 або 5×5. він ковзає по вхідних даних зображення та обчислює скалярний добуток між вагою ядра та відповідним фрагментом вхідного зображення. Вихідні дані цього шару називають картами функцій. Припустімо, що ми використовуємо загалом 12 фільтрів для цього шару, ми отримаємо вихідний обсяг розміром 32 x 32 x 12.
- Рівень активації: Додаючи функцію активації до вихідних даних попереднього рівня, рівні активації додають мережі нелінійності. він застосує функцію поелементної активації до виходу шару згортки. Деякі поширені функції активації резюме : max(0, x), Рибний , Негерметичний RELU і т. д. Об’єм залишається незмінним, тому вихідний об’єм матиме розміри 32 x 32 x 12.
- Шар об'єднання: Цей шар періодично вставляється в ковнети, і його основною функцією є зменшення розміру тому, що робить обчислення швидкими, зменшує пам’ять, а також запобігає переобладнанню. Два поширені типи шарів об'єднання максимальне об'єднання і середнє об'єднання . Якщо ми використовуємо максимальний пул із фільтрами 2 x 2 і кроком 2, результуючий об’єм матиме розмір 16x16x12.
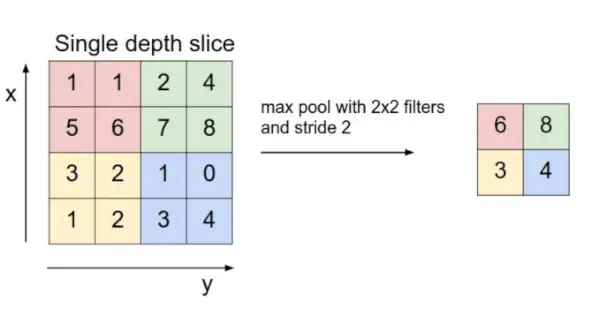
Джерело зображення: cs231n.stanford.edu
- Зведення: Отримані карти функцій зводяться в одновимірний вектор після шарів згортки та об’єднання, щоб їх можна було передати в повністю пов’язаний шар для категоризації чи регресії.
- Повністю підключені шари: Він приймає вхідні дані з попереднього рівня та обчислює остаточну класифікацію або завдання регресії.
Джерело зображення: cs231n.stanford.edu
- Вихідний рівень: Вихідні дані з повністю зв’язаних шарів потім подаються в логістичну функцію для завдань класифікації, таких як sigmoid або softmax, яка перетворює вихідні дані кожного класу в оцінку ймовірності кожного класу.
приклад:
Давайте розглянемо зображення та застосуємо шар згортки, шар активації та операцію шару об’єднання, щоб отримати внутрішню функцію.
css підкреслений текст
Вхідне зображення:
Вхідне зображення
крок:
- імпортувати необхідні бібліотеки
- встановити параметр
- визначити ядро
- Завантажте зображення та побудуйте його.
- Переформатуйте зображення
- Застосуйте операцію шару згортки та побудуйте вихідне зображення.
- Застосуйте операцію шару активації та побудуйте вихідне зображення.
- Застосуйте операцію шару об’єднання та побудуйте вихідне зображення.
Python3
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)> image>=> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
>
використання операційної системи
>
Вихід :

Оригінальне зображення в градаціях сірого
Вихід
пара java
Переваги згорткових нейронних мереж (CNN):
- Добре виявляє закономірності та особливості в зображеннях, відео та аудіосигналах.
- Стійкий до трансляції, обертання та інваріантності масштабування.
- Наскрізне навчання, немає потреби в ручному виділенні функцій.
- Може обробляти великі обсяги даних і досягати високої точності.
Недоліки згорткових нейронних мереж (CNN):
- Обчислювально дорогий у навчанні та потребує багато пам’яті.
- Може бути схильний до переобладнання, якщо недостатньо даних або використовується належна регулярізація.
- Вимагає великих обсягів даних з мітками.
- Інтерпретація обмежена, важко зрозуміти, чого навчилася мережа.
Часті запитання (FAQ)
1: Що таке згорточна нейронна мережа (CNN)?
Згорточна нейронна мережа (CNN) — це тип нейронної мережі глибокого навчання, яка добре підходить для аналізу зображень і відео. CNN використовують ряд шарів згортки та об’єднання, щоб витягти характеристики із зображень і відео, а потім використовувати ці функції для класифікації або виявлення об’єктів або сцен.
2: Як працюють CNN?
CNN працюють, застосовуючи ряд шарів згортки та об’єднання до вхідного зображення чи відео. Шари згортки витягують функції з вхідних даних, ковзаючи невеликим фільтром або ядром по зображенню чи відео та обчислюючи скалярний добуток між фільтром і вхідними даними. Потім шари об’єднання зменшують вибірку результату шарів згортки, щоб зменшити розмірність даних і зробити їх більш ефективними з точки зору обчислень.
3: Які типові функції активації використовуються в CNN?
Деякі поширені функції активації, які використовуються в CNN, включають:
- Rectified Linear Unit (ReLU): ReLU — це функція активації без насичення, ефективна з точки зору обчислень і проста в навчанні.
- Випрямлений лінійний блок із витоком (Leaky ReLU): Leaky ReLU — це варіант ReLU, який дозволяє невеликій кількості негативного градієнта проходити через мережу. Це може допомогти запобігти зникненню мережі під час навчання.
- Параметрична випрямлена лінійна одиниця (PReLU): PReLU є узагальненням Leaky ReLU, яке дозволяє вивчати нахил негативного градієнта.
4: Яка мета використання кількох шарів згортки в CNN?
Використання кількох шарів згортки в CNN дозволяє мережі вивчати дедалі складніші функції з вхідного зображення чи відео. Перші шари згортки вивчають прості елементи, такі як ребра та кути. Більш глибокі шари згортки вивчають більш складні характеристики, такі як форми та об’єкти.
5: Які поширені методи регулярізації використовуються в CNN?
Методи регуляризації використовуються, щоб запобігти CNN від переобладнання навчальних даних. Деякі поширені методи регулярізації, які використовуються в CNN, включають:
- Dropout: Dropout випадковим чином викидає нейрони з мережі під час навчання. Це змушує мережу вивчати більш надійні функції, які не залежать від жодного окремого нейрона.
- Регулярізація L1: регулярізація L1 регулярує абсолютне значення вагових коефіцієнтів у мережі. Це може допомогти зменшити кількість ваг і зробити мережу більш ефективною.
- Регулярізація L2: регулярізація L2 регулярує квадрат ваг в мережі. Це також може допомогти зменшити кількість ваг і зробити мережу більш ефективною.
6: Яка різниця між шаром згортки та шаром об’єднання?
Згортковий шар витягує функції з вхідного зображення або відео, тоді як об’єднаний рівень зменшує дискретизацію виходу згорткових шарів. Шари згортки використовують серію фільтрів для виділення функцій, тоді як шари об’єднання використовують різноманітні методи зменшення дискретизації даних, наприклад максимальне об’єднання та об’єднання середніх значень.