З моменту винаходу комп'ютерів люди використовують термін ' Дані ' для позначення комп'ютерної інформації, переданої або збереженої. Однак є дані, які також існують у типах замовлень. Даними можуть бути числа або тексти, написані на аркуші паперу, у формі бітів і байтів, що зберігаються в пам’яті електронних пристроїв, або факти, що зберігаються в свідомості людини. Коли світ почав модернізуватися, ці дані стали важливим аспектом повсякденного життя кожного, а різні реалізації дозволили зберігати їх по-різному.
Дані це набір фактів і цифр або набір значень або значень певного формату, який посилається на один набір значень елементів. Потім елементи даних класифікуються на підпункти, які є групою елементів, які не відомі як проста первинна форма елемента.
Розглянемо приклад, коли ім’я співробітника можна розбити на три підпункти: ім’я, по батькові та прізвище. Однак ідентифікатор, призначений працівнику, зазвичай вважатиметься одним елементом.
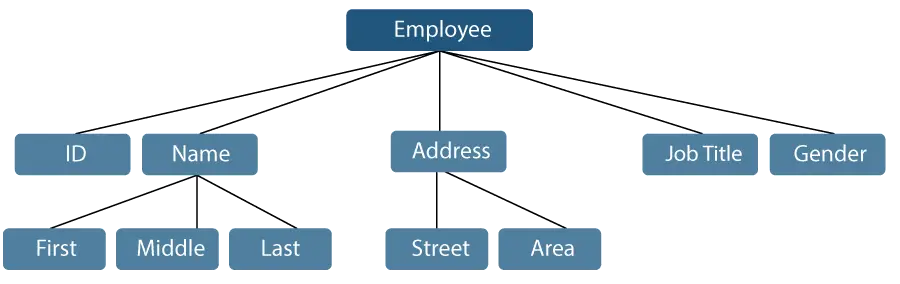
Фігура 1: Представлення елементів даних
У наведеному вище прикладі такі елементи, як ідентифікатор, вік, стать, ім’я, середина, прізвище, вулиця, місцевість тощо, є елементами елементарних даних. Навпаки, ім’я та адреса є елементами даних групи.
Що таке структура даних?
Структура даних є галуззю інформатики. Вивчення структури даних дозволяє нам зрозуміти організацію даних і управління потоком даних, щоб підвищити ефективність будь-якого процесу або програми. Структура даних — це особливий спосіб зберігання та організації даних у пам’яті комп’ютера, щоб ці дані можна було легко отримати та ефективно використовувати в майбутньому, коли це буде потрібно. Даними можна керувати різними способами, наприклад, логічною або математичною моделлю для певної організації даних, відомою як структура даних.
Обсяг конкретної моделі даних залежить від двох факторів:
- По-перше, він повинен бути достатньо завантажений у структуру, щоб відобразити певну кореляцію даних з об’єктом реального світу.
- По-друге, формування має бути настільки простим, щоб можна було адаптуватися для ефективної обробки даних, коли це необхідно.
Деякими прикладами структур даних є масиви, пов’язані списки, стеки, черги, дерева тощо. Структури даних широко використовуються майже в усіх аспектах комп’ютерних наук, наприклад, у розробці компілятора, операційних системах, графіці, штучному інтелекті та багато іншого.
Структури даних є основною частиною багатьох алгоритмів інформатики, оскільки вони дозволяють програмістам ефективно керувати даними. Воно відіграє вирішальну роль у покращенні продуктивності програми чи програмного забезпечення, оскільки головна мета програмного забезпечення — зберігати та отримувати дані користувача якомога швидше.
список створення java
Основні термінології, пов’язані зі структурами даних
Структури даних є будівельними блоками будь-якого програмного забезпечення чи програми. Вибір відповідної структури даних для програми є надзвичайно складним завданням для програміста.
Нижче наведено деякі фундаментальні термінології, які використовуються, коли йдеться про структури даних:
| Атрибути | ID | Ім'я | Стать | Назва посади |
|---|---|---|---|---|
| Цінності | 1234 | Стейсі М. Хілл | Жінка | Розробник програмного забезпечення |
Сутності зі схожими атрибутами утворюють an Набір сутностей . Кожен атрибут набору сутностей має діапазон значень, набір усіх можливих значень, які можна призначити певному атрибуту.
Термін «інформація» іноді використовується для даних із заданими атрибутами значущих або оброблених даних.
Розуміння потреби в структурах даних
Оскільки програми стають все складнішими, а обсяг даних щодня збільшується, це може призвести до проблем із пошуком даних, швидкістю обробки, обробкою кількох запитів тощо. Структури даних підтримують різні методи організації, керування та ефективного зберігання даних. За допомогою структур даних ми можемо легко переглядати елементи даних. Структури даних забезпечують ефективність, багаторазове використання та абстракцію.
Чому ми повинні вивчати структури даних?
- Структури даних і алгоритми є двома ключовими аспектами інформатики.
- Структури даних дозволяють нам упорядковувати та зберігати дані, тоді як алгоритми дозволяють обробляти ці дані змістовно.
- Вивчення структур даних і алгоритмів допоможе нам стати кращими програмістами.
- Ми зможемо написати більш ефективний і надійний код.
- Ми також зможемо вирішувати проблеми швидше та ефективніше.
Розуміння цілей структур даних
Структури даних задовольняють дві взаємодоповнюючі цілі:
Розуміння деяких ключових особливостей структур даних
Деякі з важливих особливостей структур даних:
Класифікація структур даних
Структура даних надає структурований набір змінних, пов’язаних одна з одною різними способами. Він є основою інструменту програмування, який вказує на зв’язок між елементами даних і дозволяє програмістам ефективно обробляти дані.
контроль збереженої програми
Ми можемо класифікувати структури даних на дві категорії:
- Примітивна структура даних
- Непримітивна структура даних
На наступному малюнку показано різні класифікації структур даних.

малюнок 2: Класифікації структур даних
Примітивні структури даних
- Цими структурами даних можна маніпулювати або керувати ними безпосередньо за допомогою команд машинного рівня.
- Основні типи даних, наприклад Ціле число, число з плаваючою точкою, символ , і Логічний підпадають під примітивні структури даних.
- Ці типи даних також називаються Прості типи даних , оскільки вони містять символи, які не можна розділити далі
Непримітивні структури даних
- Цими структурами даних не можна маніпулювати або працювати безпосередньо за допомогою інструкцій на рівні машини.
- Ці структури даних зосереджені на формуванні набору елементів даних, який є будь-яким однорідний (однаковий тип даних) або неоднорідний (різні типи даних).
- Виходячи зі структури та розташування даних, ми можемо розділити ці структури даних на дві підкатегорії -
- Лінійні структури даних
- Нелінійні структури даних
Лінійні структури даних
Структура даних, яка зберігає лінійний зв’язок між своїми елементами даних, відома як лінійна структура даних. Розташування даних виконується лінійно, де кожен елемент складається з наступників і попередників, за винятком першого та останнього елементів даних. Однак це не обов’язково вірно у випадку пам’яті, оскільки розташування може не бути послідовним.
На основі розподілу пам’яті лінійні структури даних далі класифікуються на два типи:
The Масив є найкращим прикладом статичної структури даних, оскільки вони мають фіксований розмір, і його дані можуть бути змінені пізніше.
Зв’язані списки, стеки , і Хвости є типовими прикладами динамічних структур даних
Типи лінійних структур даних
Нижче наведено список лінійних структур даних, які ми зазвичай використовуємо:
1. Масиви
Ан Масив це структура даних, яка використовується для збору кількох елементів даних одного типу в одну змінну. Замість того, щоб зберігати кілька значень однакових типів даних в окремих іменах змінних, ми могли б зберігати їх усі разом в одній змінній. Це твердження не означає, що нам доведеться об’єднати всі значення одного типу даних у будь-якій програмі в один масив цього типу даних. Але часто бувають випадки, коли деякі конкретні змінні одного типу даних пов’язані одна з одною у спосіб, який підходить для масиву.
Масив — це список елементів, у якому кожен елемент має унікальне місце в списку. Елементи даних масиву мають однакове ім’я змінної; однак кожен має інший номер індексу, який називається нижнім індексом. Ми можемо отримати доступ до будь-якого елемента даних зі списку за допомогою його розташування в списку. Таким чином, ключовою особливістю масивів, яку слід зрозуміти, є те, що дані зберігаються в безперервних місцях пам’яті, що дає змогу користувачам переходити між елементами даних масиву, використовуючи їхні відповідні індекси.

малюнок 3. Масив
Масиви можна розділити на різні типи:
Деякі застосування масиву:
- Ми можемо зберігати список елементів даних, що належать до одного типу даних.
- Масив діє як допоміжне сховище для інших структур даних.
- Масив також допомагає зберігати елементи даних бінарного дерева фіксованої кількості.
- Масив також діє як сховище матриць.
2. Зв'язані списки
java string concat
А Зв'язаний список є ще одним прикладом лінійної структури даних, яка використовується для динамічного зберігання набору елементів даних. Елементи даних у цій структурі даних представлені вузлами, з’єднаними за допомогою посилань або покажчиків. Кожен вузол містить два поля, інформаційне поле складається з фактичних даних, а поле вказівника складається з адреси наступних вузлів у списку. Покажчик останнього вузла зв'язаного списку складається з нульового вказівника, оскільки він ні на що не вказує. На відміну від масивів, користувач може динамічно регулювати розмір пов’язаного списку відповідно до вимог.

малюнок 4. Зв'язаний список
Зв’язані списки можна класифікувати за різними типами:
Деякі застосування пов’язаних списків:
- Зв’язані списки допомагають нам реалізувати стеки, черги, бінарні дерева та графи попередньо визначеного розміру.
- Ми також можемо реалізувати функцію операційної системи для динамічного керування пам'яттю.
- Зв’язані списки також дозволяють поліноміальну реалізацію для математичних операцій.
- Ми можемо використовувати Circular Linked List для реалізації операційних систем або функцій додатків, які виконують завдання Round Robin.
- Циркулярний пов’язаний список також корисний у слайд-шоу, коли користувачеві потрібно повернутися до першого слайда після показу останнього слайда.
- Подвійний зв’язаний список використовується для реалізації кнопок вперед і назад у браузері для переміщення вперед і назад на відкритих сторінках веб-сайту.
3. Стеки
А Стек це лінійна структура даних, яка слідує за ЛІФО Принцип (останній увійшов, перший вийшов), який дозволяє виконувати такі операції, як вставка та видалення з одного кінця стека, тобто зверху. Стеки можуть бути реалізовані за допомогою безперервної пам'яті, масиву, і несуміжної пам'яті, зв'язаного списку. Приклади Стосів із реального життя – це купи книг, колода карт, купи грошей та багато іншого.

малюнок 5. Реальний приклад стека
Наведений вище малюнок представляє реальний приклад стека, де операції виконуються лише з одного кінця, як-от вставлення та видалення нових книг із верхньої частини стеку. Це означає, що вставлення та видалення в стеку можна виконувати лише з верхньої частини стеку. У будь-який момент ми можемо отримати доступ лише до вершин стека.
Основні операції в стеку такі:

Малюнок 6. Стек
Деякі застосування стеків:
- Стек використовується як тимчасова структура зберігання для рекурсивних операцій.
- Стек також використовується як допоміжна структура зберігання для викликів функцій, вкладених операцій і відкладених/відкладених функцій.
- Ми можемо керувати викликами функцій за допомогою стеків.
- Стеки також використовуються для оцінки арифметичних виразів у різних мовах програмування.
- Стеки також корисні для перетворення інфіксних виразів у постфіксні вирази.
- Стеки дозволяють перевірити синтаксис виразу в середовищі програмування.
- Ми можемо порівняти дужки за допомогою стеків.
- Стеки можна використовувати для перевертання рядка.
- Стеки корисні у вирішенні проблем, заснованих на ретрокурсі.
- Ми можемо використовувати стеки для пошуку в глибину в обході графів і дерев.
- Стеки також використовуються у функціях операційної системи.
- Стеки також використовуються у функціях UNDO і REDO під час редагування.
4. Хвости
А Черга це лінійна структура даних, подібна до стеку, з деякими обмеженнями щодо вставки та видалення елементів. Вставлення елемента в чергу виконується на одному кінці, а видалення — на іншому або протилежному кінці. Таким чином, ми можемо зробити висновок, що структура даних черги дотримується принципу FIFO (першим прийшов, першим вийшов) для маніпулювання елементами даних. Реалізацію черг можна виконати за допомогою масивів, пов’язаних списків або стеків. Деякі реальні приклади черг – це черга біля каси, ескалатор, автомийка та багато іншого.

Малюнок 7. Реальний приклад черги
Наведене вище зображення є реальною ілюстрацією каси квитків у кінотеатр, яка може допомогти нам зрозуміти чергу, де клієнт, який приходить першим, завжди обслуговується першим. Клієнт, який прийшов останнім, безсумнівно, буде обслужений останнім. Обидва кінці черги відкриті та можуть виконувати різні операції. Іншим прикладом є лінія фуд-корту, куди клієнт вставляється з заднього кінця, а клієнт видаляється з переднього кінця після надання послуги, яку він просив.
Нижче наведено основні операції черги:

Малюнок 8. Черга
Деякі застосування черг:
- Черги зазвичай використовуються в операції пошуку в ширину в Graphs.
- Черги також використовуються в операціях планувальника завдань операційних систем, як-от буферна черга клавіатури для зберігання натиснутих користувачами клавіш і буферна черга друку для зберігання документів, надрукованих принтером.
- Черги відповідають за планування ЦП, планування завдань і планування дисків.
- Пріоритетні черги використовуються в операціях завантаження файлів у браузері.
- Черги також використовуються для передачі даних між периферійними пристроями та ЦП.
- Черги також відповідають за обробку переривань, створених програмами користувача для ЦП.
Нелінійні структури даних
Нелінійні структури даних — це структури даних, у яких елементи даних розташовані не в послідовному порядку. Тут вставка та видалення даних неможливі лінійним способом. Між окремими елементами даних існує ієрархічний зв’язок.
Типи нелінійних структур даних
Нижче наведено список нелінійних структур даних, які ми зазвичай використовуємо:
1. Дерева
Дерево — це нелінійна структура даних та ієрархія, що містить набір вузлів, так що кожен вузол дерева зберігає значення та список посилань на інші вузли («дочірні»).
Деревоподібна структура даних — це спеціалізований метод упорядкування та збору даних у комп’ютері для більш ефективного використання. Він містить центральний вузол, структурні вузли та підвузли, з’єднані ребрами. Ми також можемо сказати, що структура даних дерева складається з коренів, гілок і листя, з’єднаних між собою.

Малюнок 9. Дерево
перетворення рядка на дату
Дерева можна розділити на кілька видів:
Деякі застосування дерев:
- Дерева реалізують ієрархічні структури в комп’ютерних системах, таких як каталоги та файлові системи.
- Дерева також використовуються для реалізації структури навігації веб-сайту.
- Ми можемо створити код, подібний до коду Хаффмана, використовуючи Дерева.
- Дерева також допомагають приймати рішення в ігрових програмах.
- Дерева відповідають за реалізацію пріоритетних черг для функцій планування ОС на основі пріоритетів.
- Дерева також відповідають за розбір виразів і операторів у компіляторах різних мов програмування.
- Ми можемо використовувати Дерева для зберігання ключів даних для індексування системи керування базами даних (СУБД).
- Spanning Trees дозволяє нам маршрутизувати рішення в комп’ютерних і комунікаційних мережах.
- Дерева також використовуються в алгоритмі пошуку шляху, реалізованому в додатках штучного інтелекту (AI), робототехніки та відеоігор.
2. Графіки
Граф є ще одним прикладом нелінійної структури даних, що містить кінцеву кількість вузлів або вершин і ребер, що їх з’єднують. Графіки використовуються для вирішення проблем реального світу, у якому вони позначають проблемну область як мережу, таку як соціальні мережі, комунікаційні мережі та телефонні мережі. Наприклад, вузли або вершини графа можуть представляти одного користувача в телефонній мережі, тоді як ребра представляють зв’язок між ними через телефон.
Структура даних графа G вважається математичною структурою, що складається з набору вершин V і набору ребер E, як показано нижче:
G = (V,E)

Малюнок 10. Графік
Наведений вище малюнок представляє граф, що має сім вершин A, B, C, D, E, F, G і десять ребер [A, B], [A, C], [B, C], [B, D], [B, E], [C, D], [D, E], [D, F], [E, F] і [E, G].
Залежно від положення вершин і ребер, графи можна класифікувати на різні типи:
Деякі застосування графіків:
- Графіки допомагають нам представляти маршрути та мережі в програмах транспорту, подорожей і зв’язку.
- Графіки використовуються для відображення маршрутів у GPS.
- Графіки також допомагають нам представити взаємозв’язки в соціальних мережах та інших мережевих програмах.
- Графіки використовуються в картографічних програмах.
- Графіки відповідають за представлення переваг користувача в програмах електронної комерції.
- Графіки також використовуються в комунальних мережах для виявлення проблем, які постають перед місцевими або муніципальними корпораціями.
- Графіки також допомагають керувати використанням і доступністю ресурсів в організації.
- Графіки також використовуються для створення карт посилань на документи веб-сайтів, щоб відобразити зв’язок між сторінками за допомогою гіперпосилань.
- Графіки також використовуються в роботах і нейронних мережах.
Основні операції зі структурами даних
У наступному розділі ми обговоримо різні типи операцій, які ми можемо виконувати для маніпулювання даними в кожній структурі даних:
- Час компіляції
- Час виконання
Наприклад, malloc() функція використовується в мові C для створення структури даних.
Розуміння абстрактного типу даних
Відповідно до Національний інститут стандартів і технологій (NIST) , структура даних — це розташування інформації, як правило, у пам’яті, для підвищення ефективності алгоритму. Структури даних включають пов’язані списки, стеки, черги, дерева та словники. Вони також можуть бути теоретичною сутністю, як ім’я та адреса особи.
З наведеного вище визначення можна зробити висновок, що операції в структурі даних включають:
- Високий рівень абстракцій, наприклад додавання або видалення елемента зі списку.
- Пошук і сортування елемента в списку.
- Доступ до елемента з найвищим пріоритетом у списку.
Кожного разу, коли структура даних виконує такі операції, вона називається an Абстрактний тип даних (ADT) .
додати до масиву в java
Ми можемо визначити його як набір елементів даних разом із операціями над даними. Термін «абстрактний» означає той факт, що дані та визначені над ними фундаментальні операції вивчаються незалежно від їх реалізації. Це стосується того, що ми можемо робити з даними, а не того, як ми можемо це зробити.
Реалізація ADI містить структуру зберігання для зберігання елементів даних і алгоритмів для основних операцій. Усі структури даних, такі як масив, пов’язаний список, черга, стек тощо, є прикладами ADT.
Розуміння переваг використання ADT
У реальному світі програми розвиваються як наслідок нових обмежень або вимог, тому модифікація програми зазвичай вимагає зміни однієї або кількох структур даних. Наприклад, припустімо, що ми хочемо вставити нове поле в запис про працівника, щоб відстежувати більше деталей про кожного працівника. У такому випадку ми можемо підвищити ефективність програми, замінивши масив на зв’язану структуру. У такій ситуації переписування кожної процедури, яка використовує модифіковану структуру, є непридатним. Отже, кращою альтернативою є відокремлення структури даних від інформації про її реалізацію. Це принцип використання абстрактних типів даних (ADT).
Деякі застосування структур даних
Нижче наведено деякі застосування структур даних:
- Структури даних допомагають в організації даних у пам’яті комп’ютера.
- Структури даних також допомагають у представленні інформації в базах даних.
- Структури даних дозволяють реалізувати алгоритми пошуку в даних (наприклад, пошукова система).
- Ми можемо використовувати структури даних для реалізації алгоритмів для маніпулювання даними (наприклад, текстові процесори).
- Ми також можемо реалізувати алгоритми для аналізу даних за допомогою структур даних (наприклад, майнери даних).
- Структури даних підтримують алгоритми для створення даних (наприклад, генератор випадкових чисел).
- Структури даних також підтримують алгоритми для стиснення та розпакування даних (наприклад, утиліта zip).
- Ми також можемо використовувати структури даних для реалізації алгоритмів шифрування та дешифрування даних (наприклад, системи безпеки).
- За допомогою структур даних ми можемо створити програмне забезпечення, яке може керувати файлами та каталогами (наприклад, файловий менеджер).
- Ми також можемо розробити програмне забезпечення, яке може відтворювати графіку за допомогою структур даних. (Наприклад, веб-браузер або програмне забезпечення для 3D-візуалізації).
Крім того, як згадувалося раніше, існує багато інших програм структур даних, які можуть допомогти нам створити будь-яке програмне забезпечення.